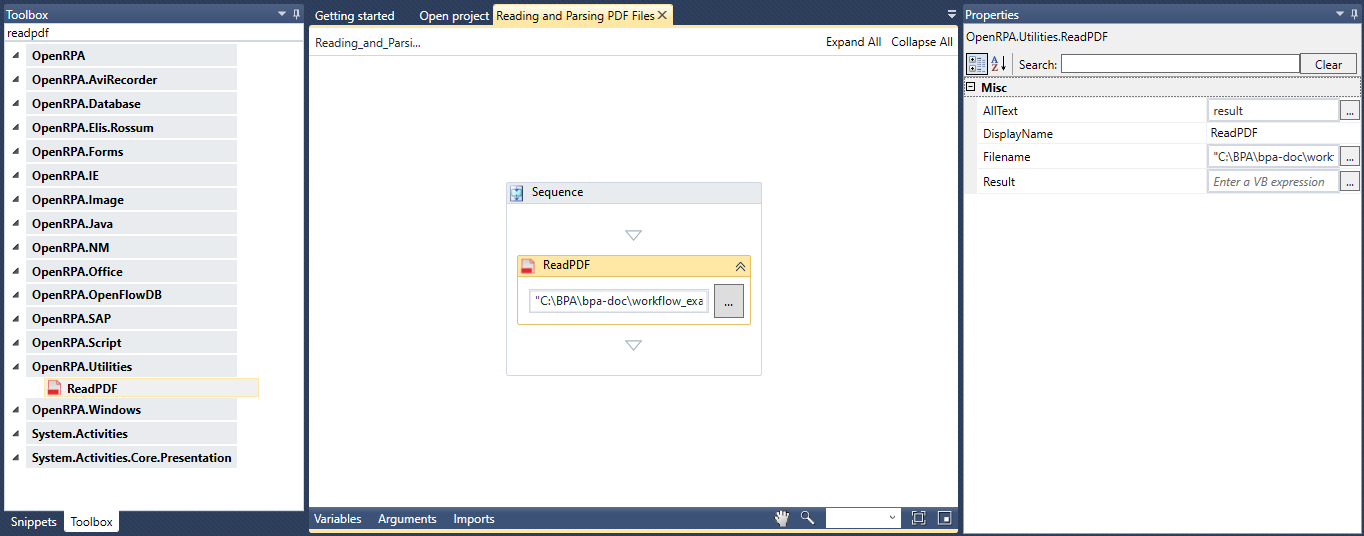
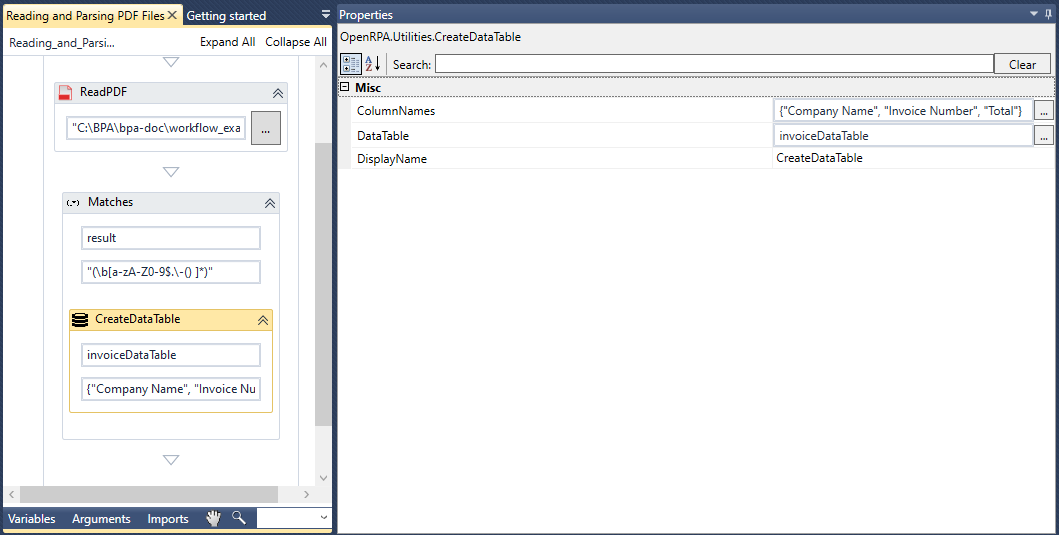
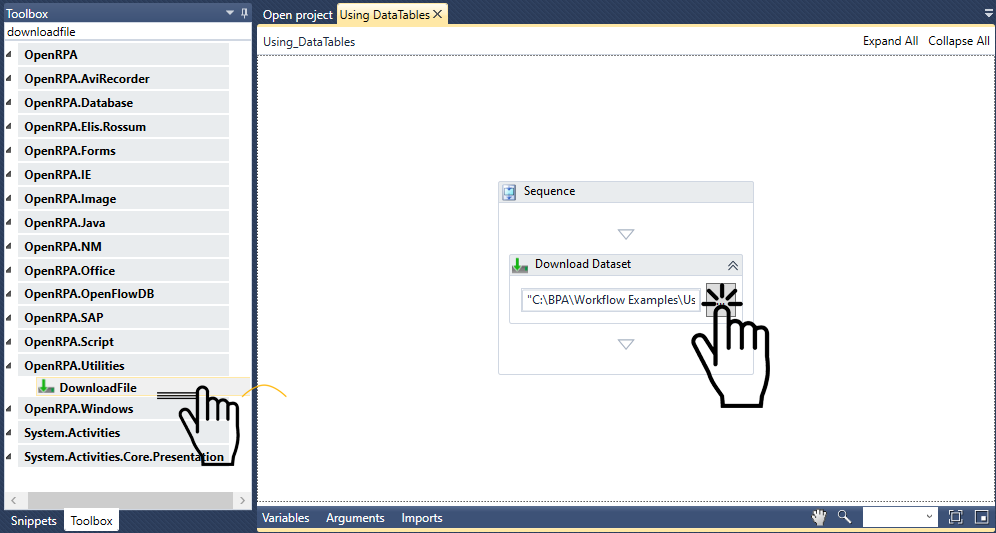
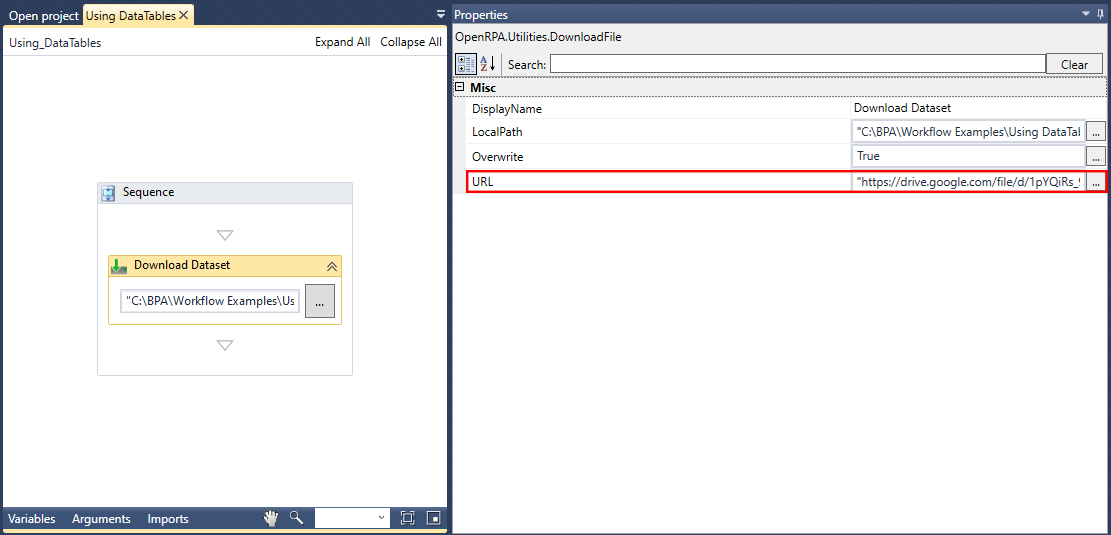
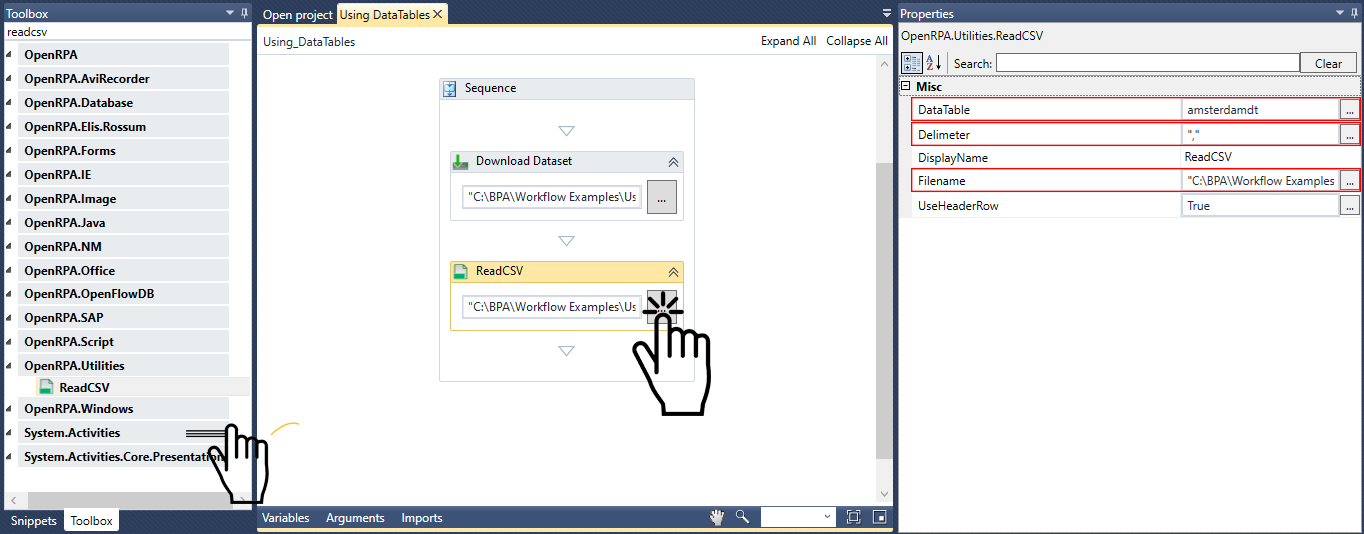
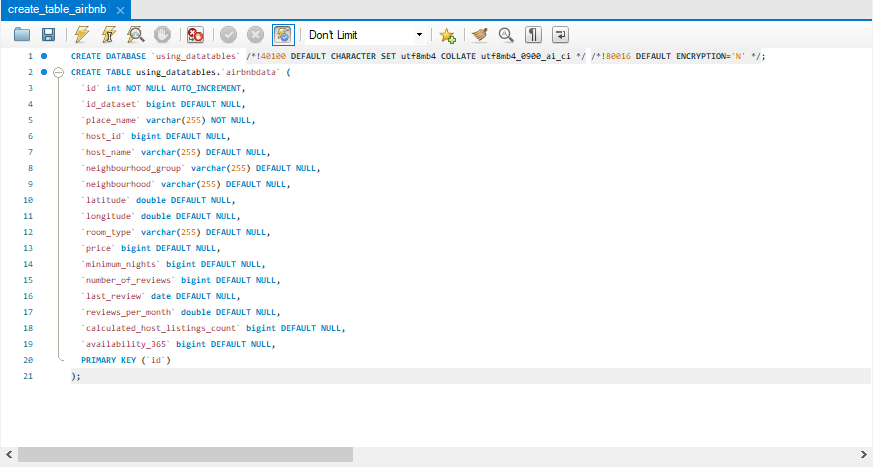
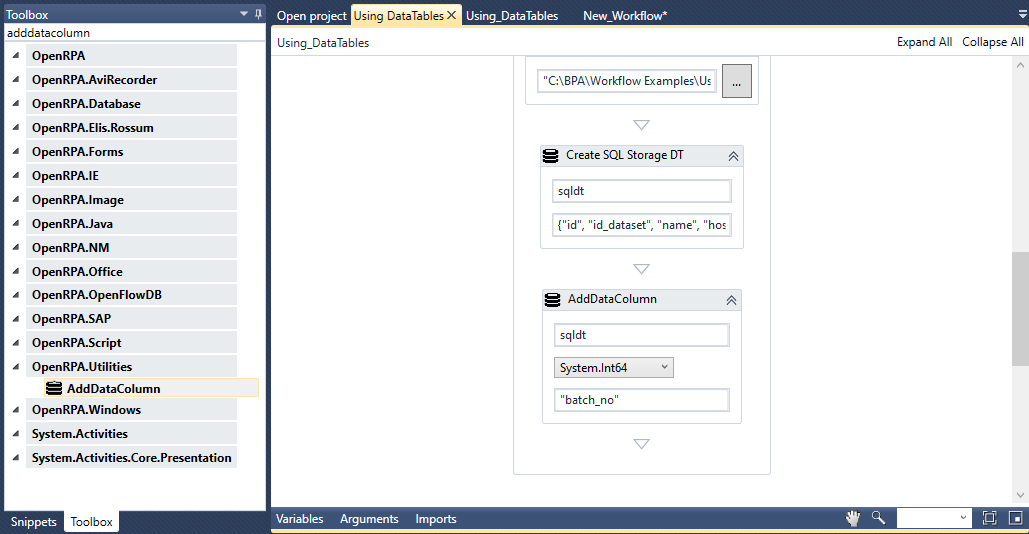
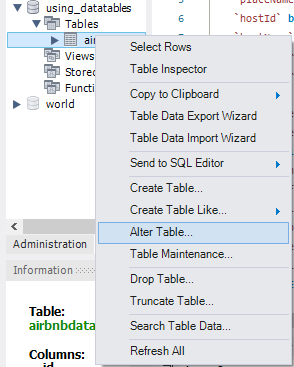
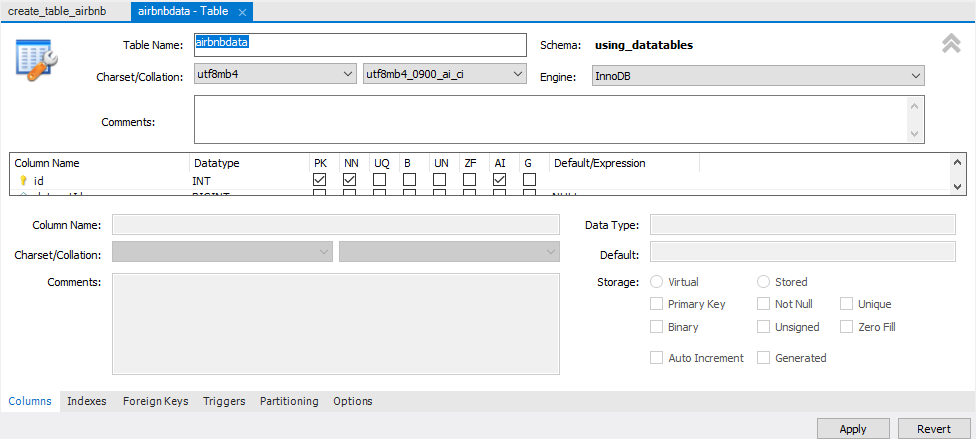
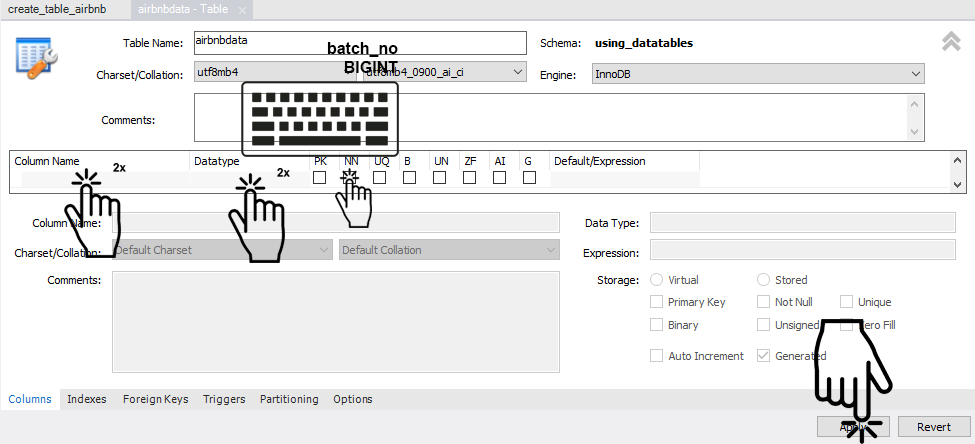
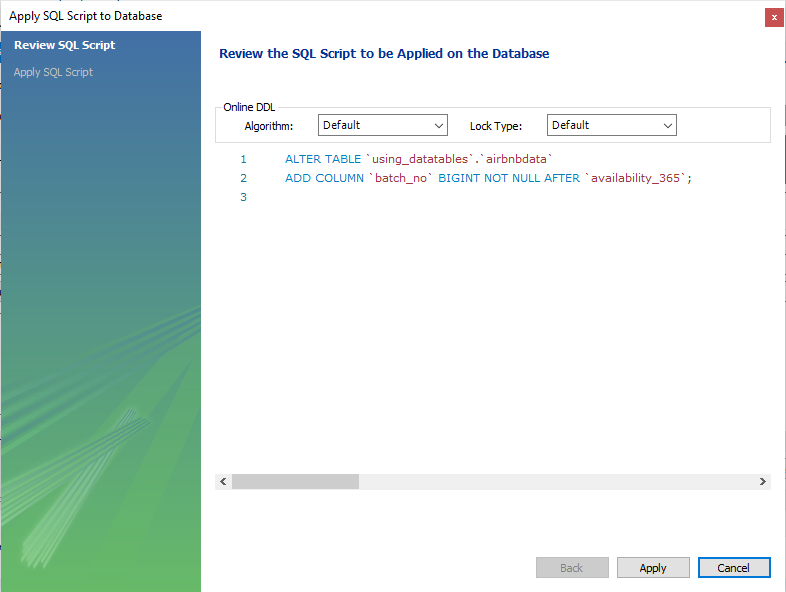
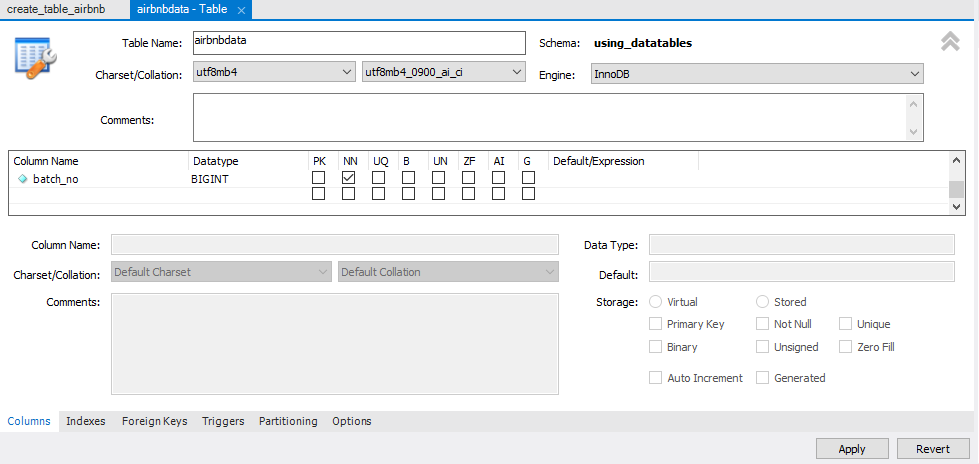
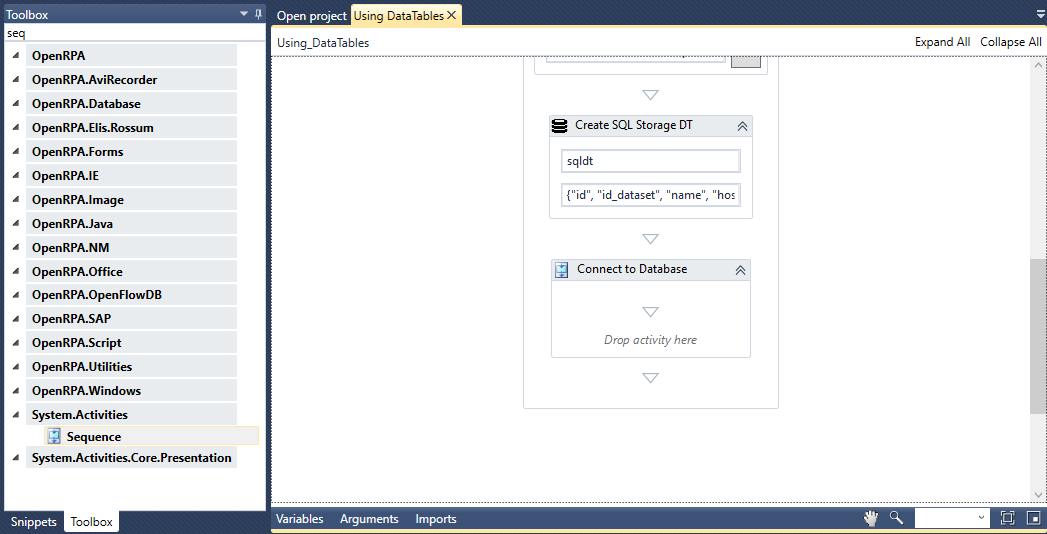
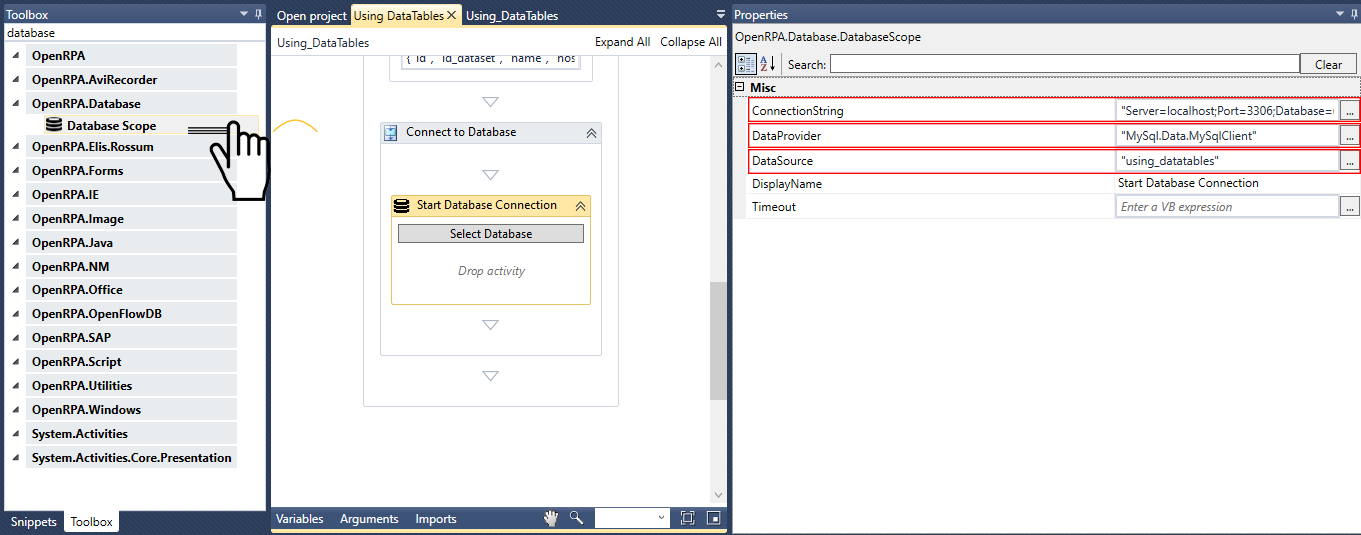
このセクションでは、SQL Tableに
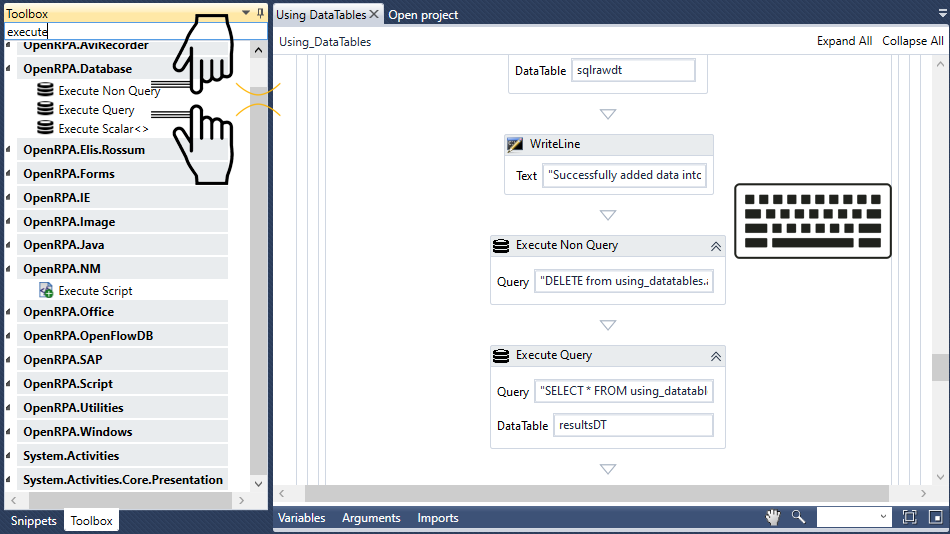
まず、[Execute Non Query ]アクティビティを[Database Scope SQL クエリを Int32
ここでは、任意の項目、つまり217の return217
クエリフィールド 実行 する クエリを 含むフィールド)の中に「DELETE from using_datatables.airbnbdata WHERE id = 217 id Property Boxの Result Ctrl+Kを押して return217という 1を Int32
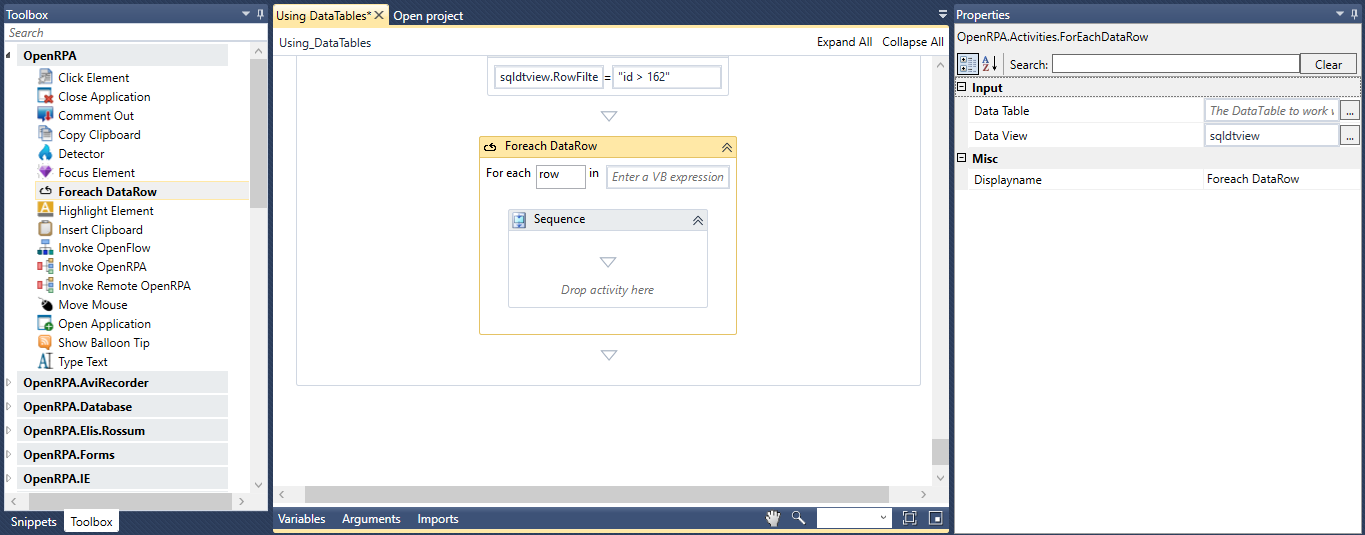
ここで、[クエリ実行] アクティビティを[データベース スコープ]
SELECT * FROM using_datatables.airbnbdata;” をQuery 実行 する Query を 含む)に挿入し、resultsDT DataTable 結果を 保存 する DataTable を Ctrl+K airbnbdata SQL テーブルから resultsDT DataTableに
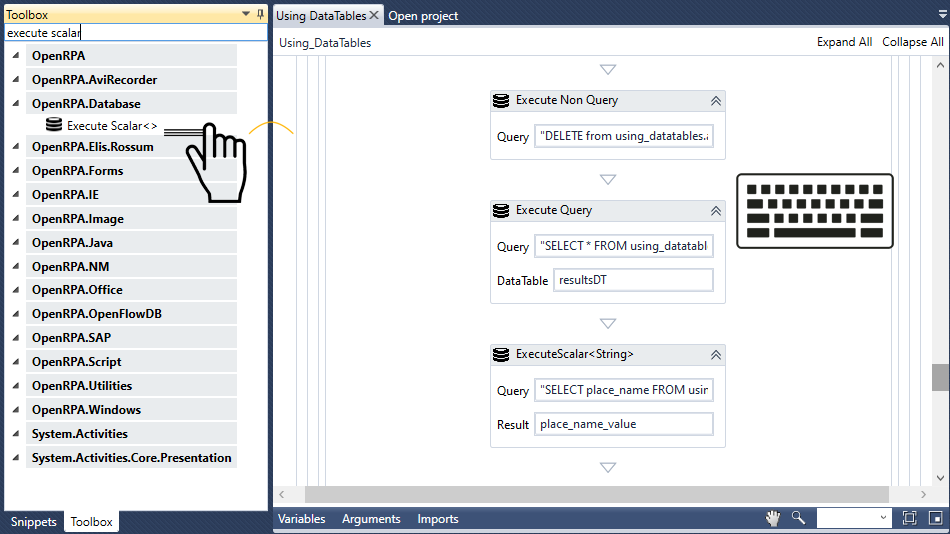
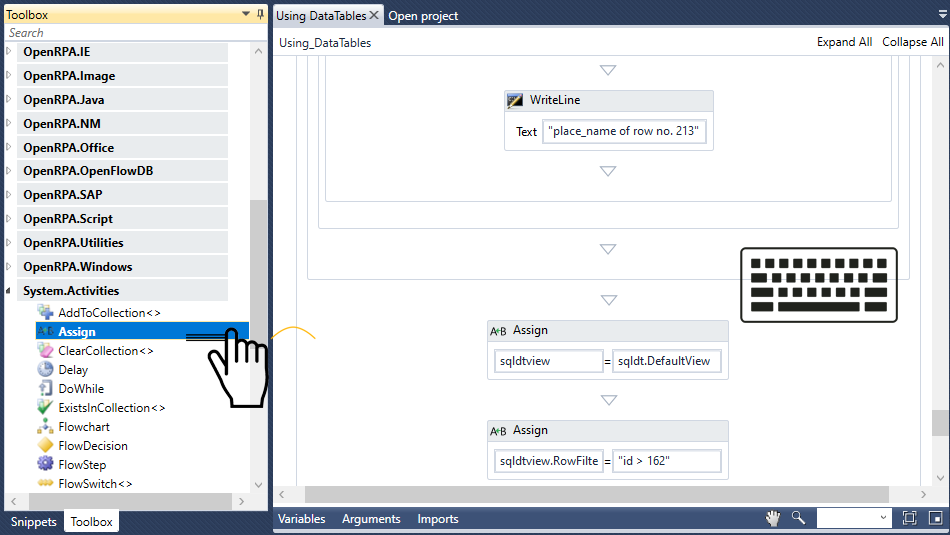
ここでは、任意の項目(たとえば213 場所名を place_name_value
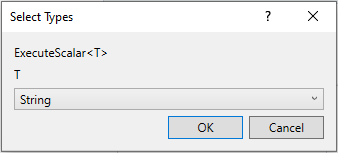
ここで、Execute Scalar<> アクティビティをDatabase Scope クエリによって String 「SELECT place_name FROM using_datables.airbnbdata WHERE id = 213 クエリーフィールド 実行 する クエリー )に挿入し、「place_name_value 結果 クエリーの 結果 )に入力してください。このクエリは、ID 213を 場所名の place_name_value
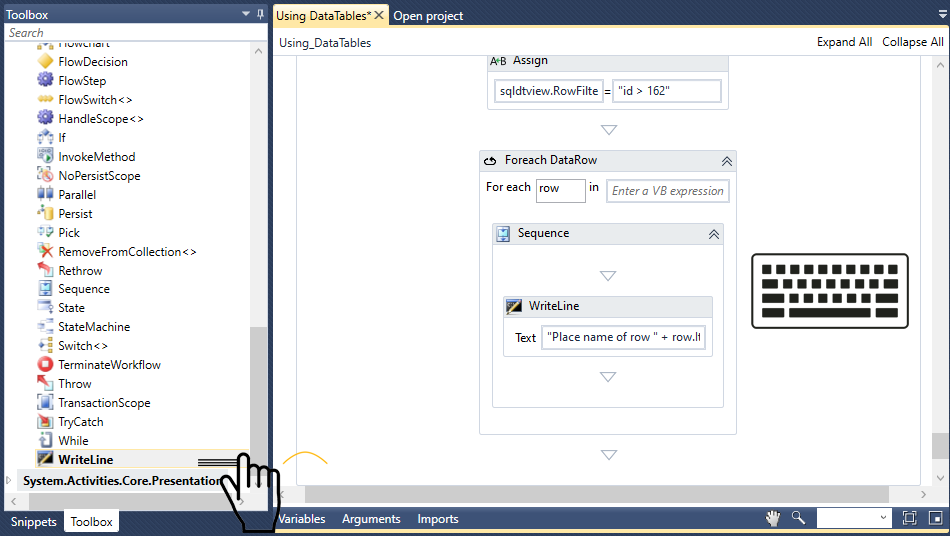
これでユーザーは挿入されたデータを視覚化することができます。
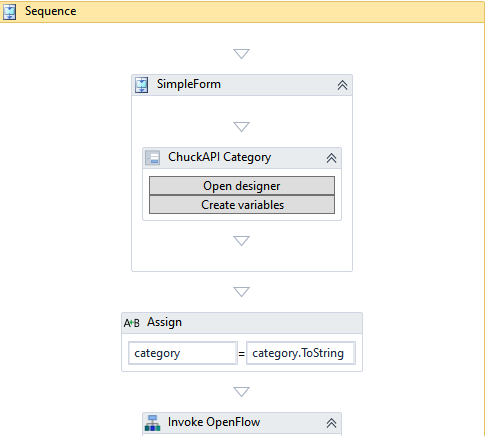
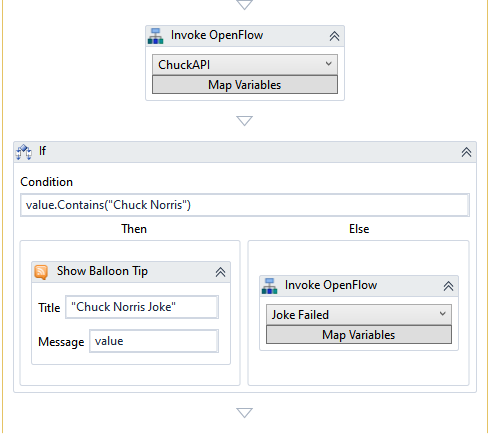
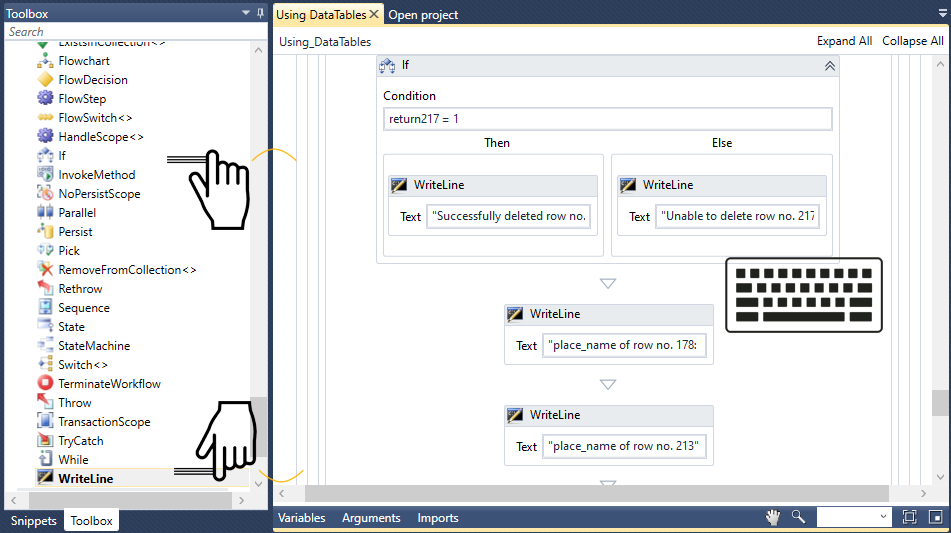
最初の値 –return217 If Activity を使用してその値が1
If アクティビティをDatabase Scope 条件 VB 式を 含むフィールド)の中に、return217 = 1を
WriteLine アクティビティをIf アクティビティの中のThen Text Enter a VB Expressionを 「Successfully deleted row no. 217」と
次に、WriteLine アクティビティをIf アクティビティ内のElse Text Enter a VB Expression 「Unable to delete row no. 217」と 217に idを
WriteLine アクティビティをDatabase Scope Enter a VB Expression Text 「place_name of row no. 178: " + resultsDT.Rows(178).Item(2).ToString Execute Query アクティビティで収集したテーブルの178番目の place_nameの
最後に、WriteLine アクティビティをもう1つ、Database Scope 行 番号 213の 場所名 " + 場所名_値 “を挿入してください。これで、Execute Scalar<> アクティビティで実行されたクエリから収集された値が表示されます。