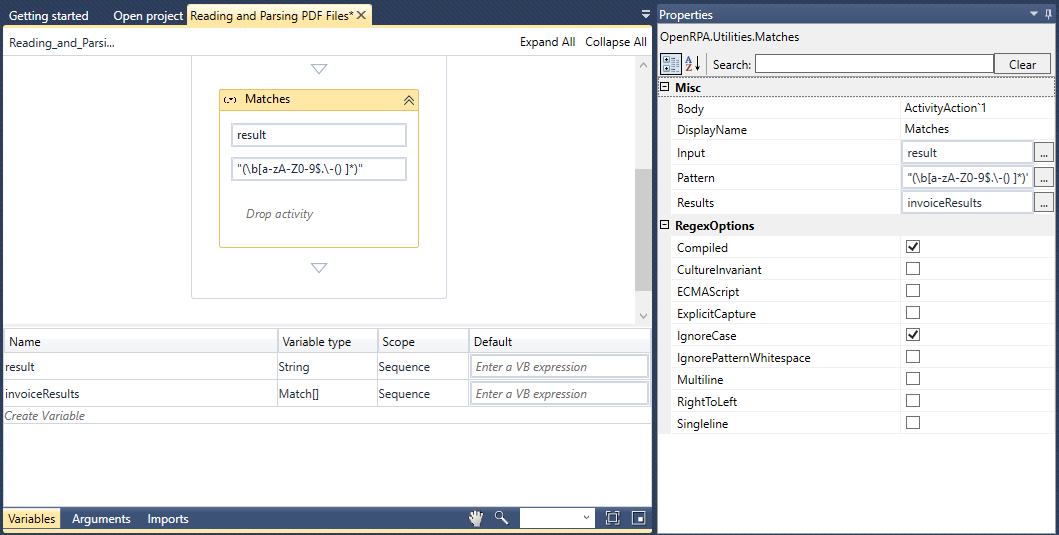
さて、ユーザーはMatchesアクティビティを使用して、ReadPDFが返す文字列からデータのグループを抽出します。
まず、MatchesActivityをメインシーケンスにドラッグします。
最初の入力ボックスには、プレースホルダー「The input string to match against」が入っており、ユーザーは変数の内容、つまり前のセクションで取り込んだテキストを挿入することになります。
2つ目の入力ボックスには、データをグループに分けるために使用するRegExパターンを挿入します。ここで使われているのは、( \b[a-zA-Z0-9$.\-() ]*)です。正規表現についての詳しい説明は、RyansTutorials Regular Expressions(https://ryanstutorials.net/regular-expressions-tutorial/)を参照してください。RegExパターンは文字列としてキャプチャされるので、引用符で囲む必要があることをユーザーに思い出させるのは興味深いことです。また,必要に応じて,グループのマッチングやパターンのテストにRegex101(https://regex101.com/) を使うことが推奨される.
また、Properties Boxの Resultsパラメータで、マッチングを保存する変数(この例ではinvoiceResults)を設定する必要があります。これは、Match listまたは単にMatch[]というタイプで構成されます。下の画像にあるように