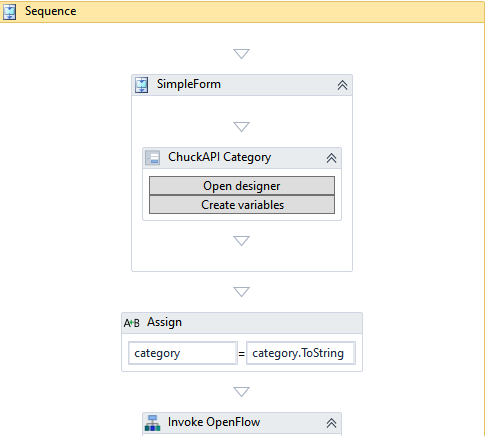
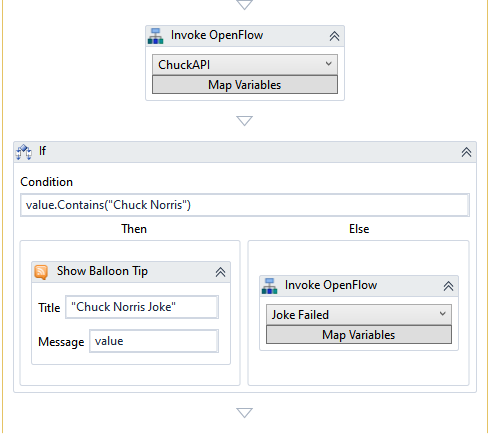
ChuckAPI
ワークフローロジック
Workflow In
Workflow In の Queue name
キュー名は完全に任意であり、ユーザは好きな名前を選ぶことができる。この例では、jokefailed
備考
Node-RED ワークスペース内のノードのプロパティにアクセスするには、指定されたノードをダブルクリックします。ノードのプロパティボックスが 表示され、それ自体に必要な各入力フィールドが表示されます。
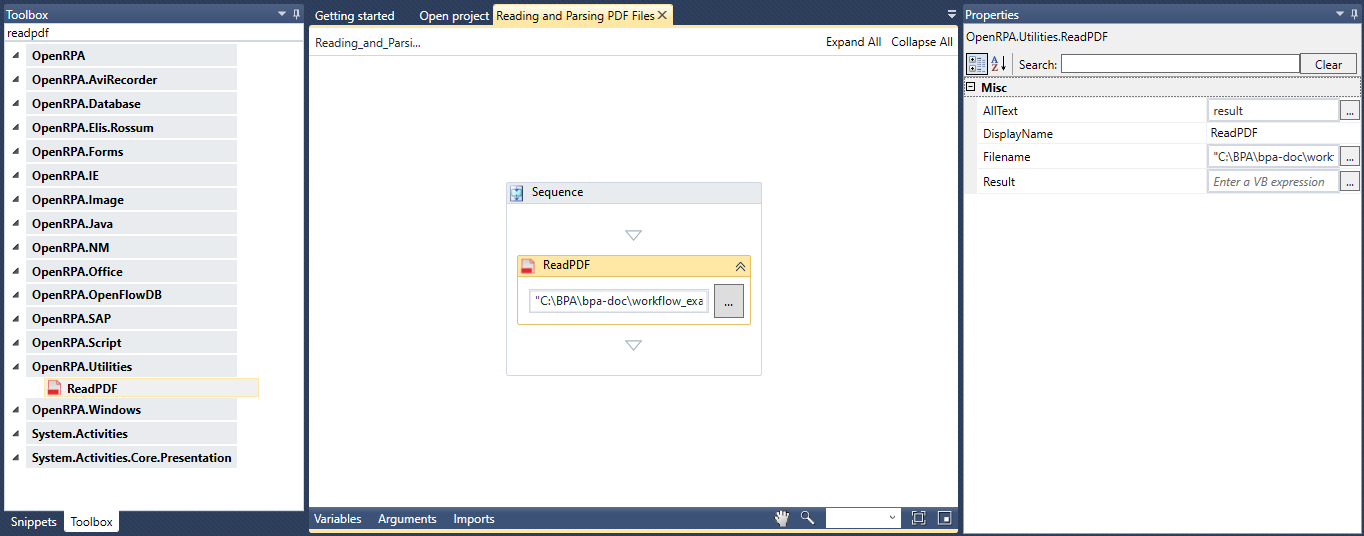
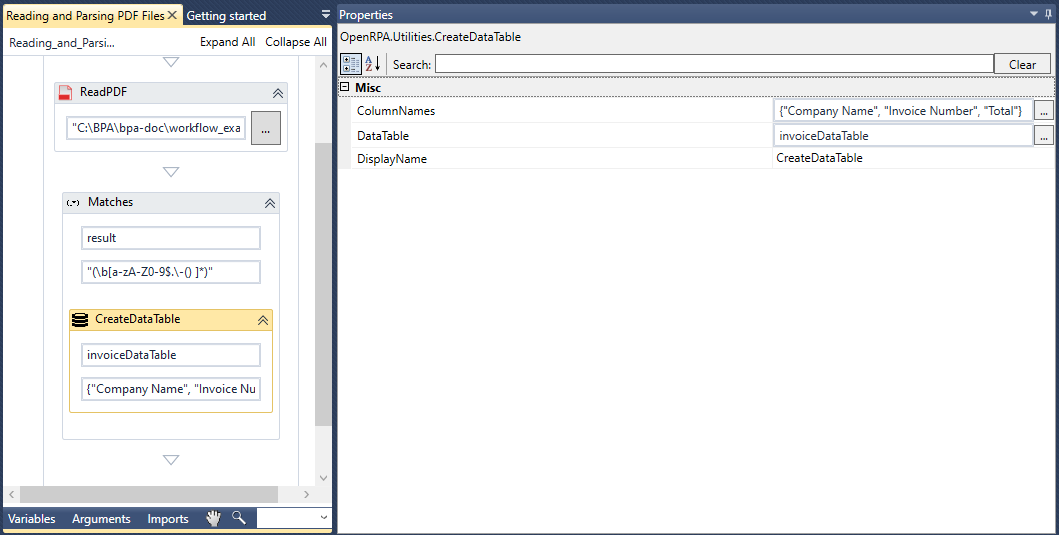
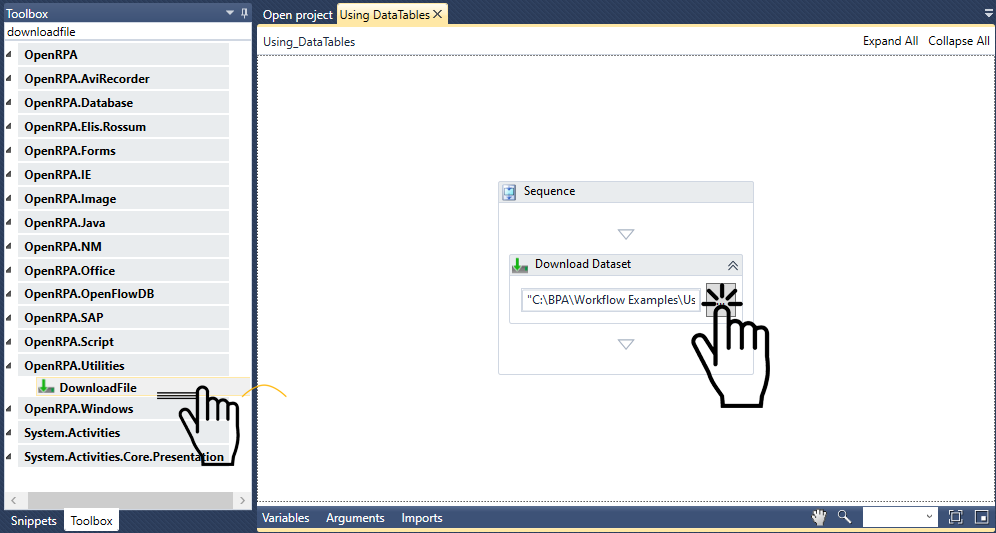
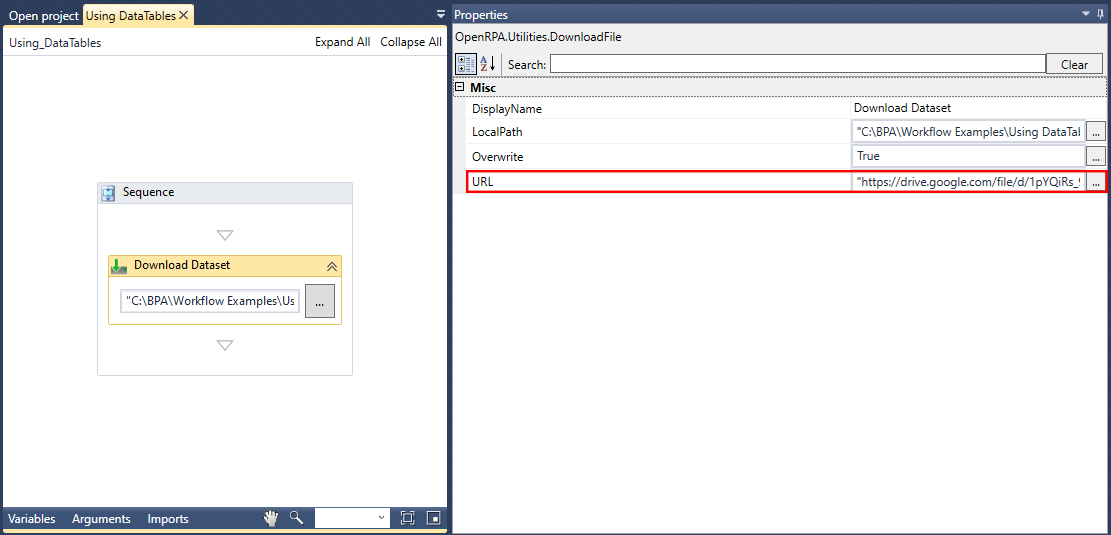
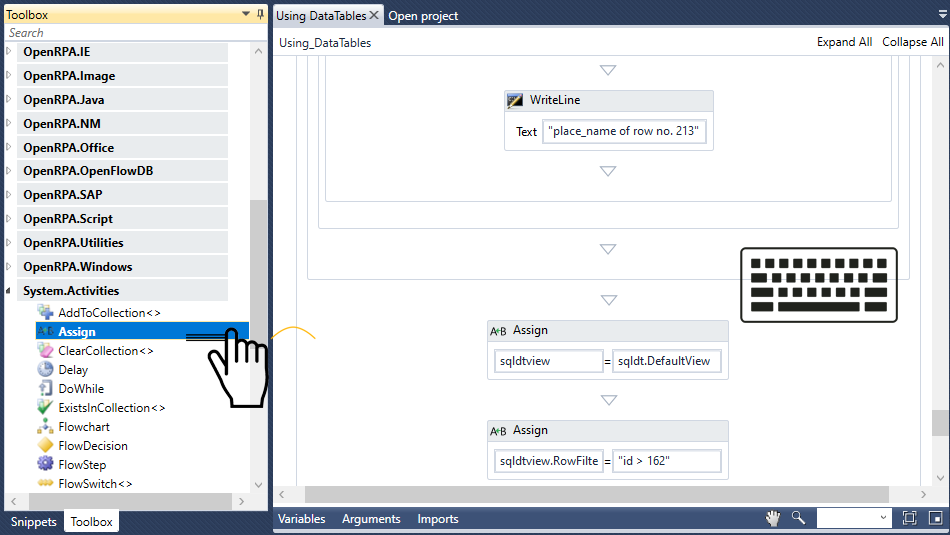
RPA
Name Joke Failed
RPA Workflow Robot REST Workflow - Joke Failed
ワークフローを呼び出すロボットと ワークフローを ロボット Local queue nameと Nameを
ローカル キュー 名は
Name
この例では、Local queue nameを jokefailed Nameを Invoke Joke Failed Workflowに
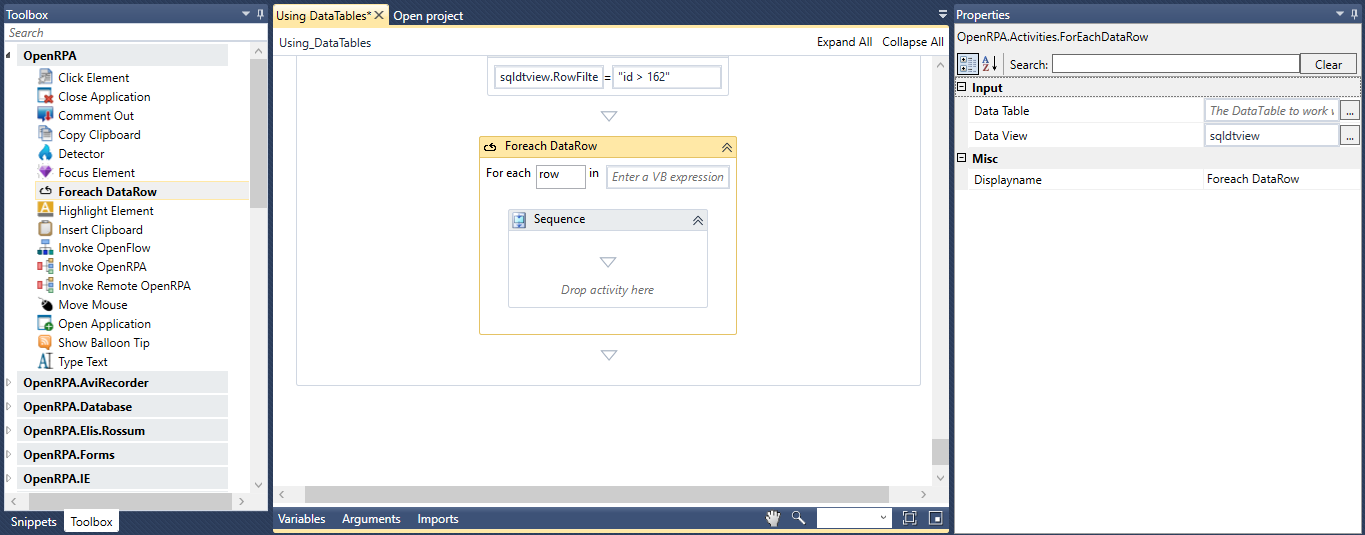
Workflow In Robot
備考
ノードの接続は、Ctrl Ctrl
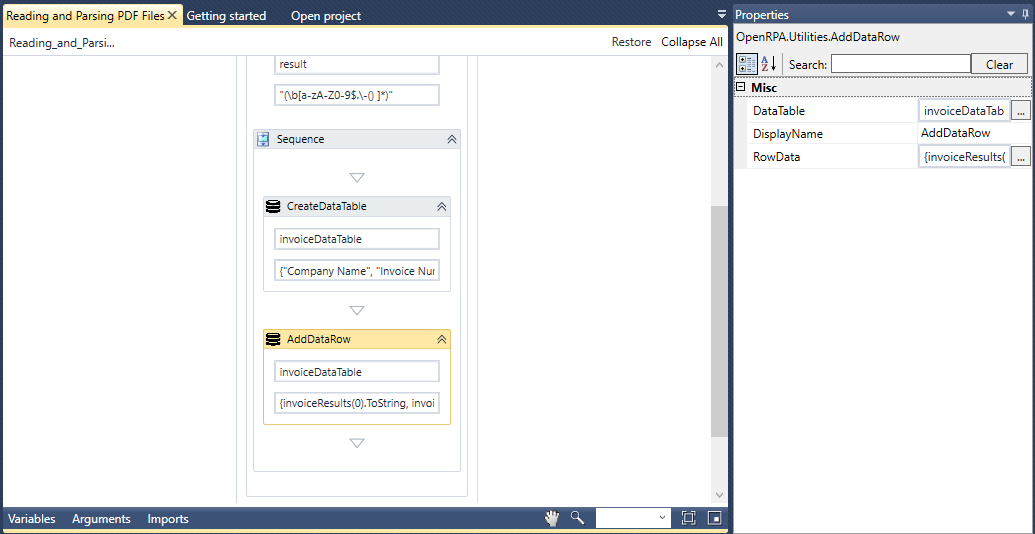
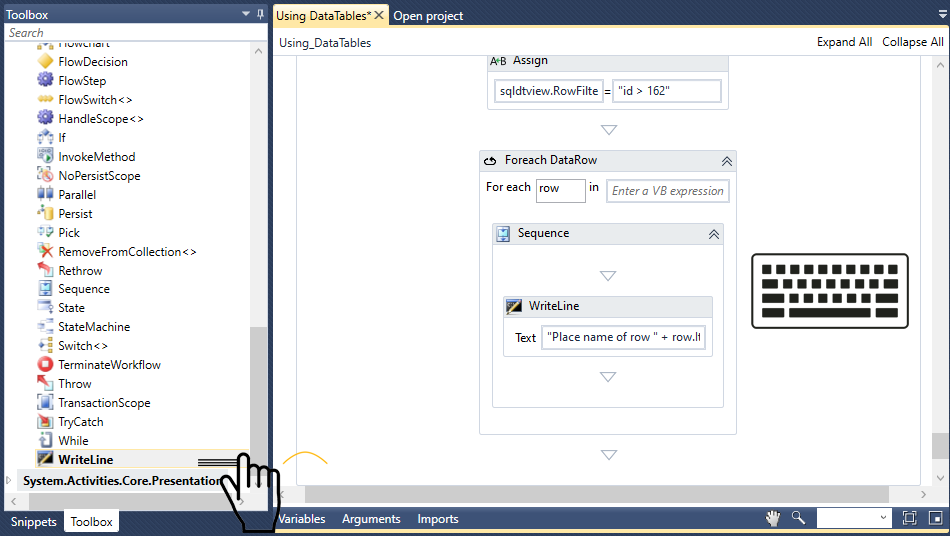
Email Out msg.payload
Invoke Joke Failed Workflow email
備考
ノードの接続は、Ctrl Ctrl
Eメール
To
Useridは admin@openiap.io admin
パスワード
この例では、ダミーの電子メール(admin@gmail.com
備考
ユーザーが Gmail の SMTP サーバを使用している場合、Less secure アプリのアクセスを 許可する設定が正しいことが必要です。さもなければ、ワークフローの実行時にエラーメッセージが表示されます。そのためには、Less secure app access (https://myaccount.google.com/lesssecureapps) Allow less secure apps ON
Workflow Out
Workflow Out」 Eメール」 admin@gmail.com
備考
ノードの接続は、Ctrl Ctrl
画面左上の赤い「Deploy」ボタンをクリックして、フローをデプロイします。
備考
Node-REDのフローに変更があった場合、ユーザーはそのフローをデプロイする必要があり、その変更は現在そのフローを使用しているロボット全体に伝搬されます。