
Coming soon – Work in progress
OpenIAPカテゴリー: BPA/OpenIAP Docs翻訳
4.5.4. ワークフローイン
このノードは、OpenFlowに新しいワークフローを作成します。ワークフローページ(http://demo.openiap.io/#/Workflows) か、OpenFlow インスタンスの“Workflows” ページ (通常/#/Workflows) で確認できます。
作成されたワークフローは、このノードを起点とした実行チェーンを持つことができます。このノードにRPAワークフローのノードを配線することで、RPA ワークフローを実行することができる。
ワークフローは、「Workflows」ページ内の「Invoke」ボタンをクリックするか、OpenRPA内のNode-REDノードまたはAssign OpenFlowアクティビティを使用してそのインスタンスを作成することによっても呼び出すことが可能です。
注意点として、 ワークフローインノードが開始した実行フローの末尾には、必ず ワークフローアウトノードが追加されている必要があります。
このノードを含むフローをデプロイすると、ユーザーによって キュー 名が付加されたロールが作成されます。他のユーザーがアクセスすることを希望する場合は、ロールページでユーザーを追加する必要があります。
ユーザーは、この実行フローで使用するフォームを、Workflow Outノードを使用して定義し、作成することもできます。ユーザーがフォームを知らない場合は、フォームの項を参照してください。
また
プロパティ
キュー 名–OpenFlow経由でアクセスした場合のワークフローの名前。
RPA– このオプションは、ワークフローが OpenRPAロボットによって起動されるかどうかを指定します。
WEB– このオプションは、ワークフローをウェブ経由で(つまり、OpenFlowサーバー経由で)起動するかどうかを指定します。
Name–ノードの 表示 名。
4.5.5. ワークフローのアウト
このノードは、「Workflow In」ノードで作成されたワークフローのアウトプットを表しま す。また、OpenFlow Form(詳細はフォームの項を参照)を定義することができ、入力データを挿入したり、他のワークフローに連鎖させたりすることが可能です。
このノードを含むフローをデプロイすると、ユーザーによって キュー 名が付加されたロールが作成されます。他のユーザーがアクセスすることを希望する場合は、ロールページでユーザーを追加する必要があります。
ユーザーは、この実行フローで使用するフォームを、Workflow Outノードを使用して定義し、作成することもできます。ユーザーがフォームを知らない場合は、フォームの項を参照してください。
プロパティ
状態– ここでは、アイドル、完了、失敗の3つのオプションがあります。
Userform– ユーザーの入力データを収集するためのフォームを定義します。
Name–ノードの 表示 名。
4.6. 流れの例
Coming soon – Work in progress
4.6.1.1. OpenFlowでフォームを作成する
このセクションでは、OpenFlow でフォームを作成する方法を学びます。フォームが何なのか分からない場合は、フォームのセクションを参照してください。
まず最初に、"Hello from OpenFlow!“など、ユーザーが挿入した入力をNode-REDに渡すためのフォームを設定します。
Forms ページ(デフォルトはhttp://demo.openiap.io/#/Forms )に移動し、Add Formボタンをクリックします。
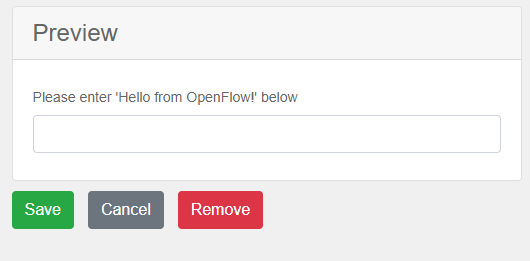
次に、テキスト フィールドのフォームをフォームデザイナにドラッグします。
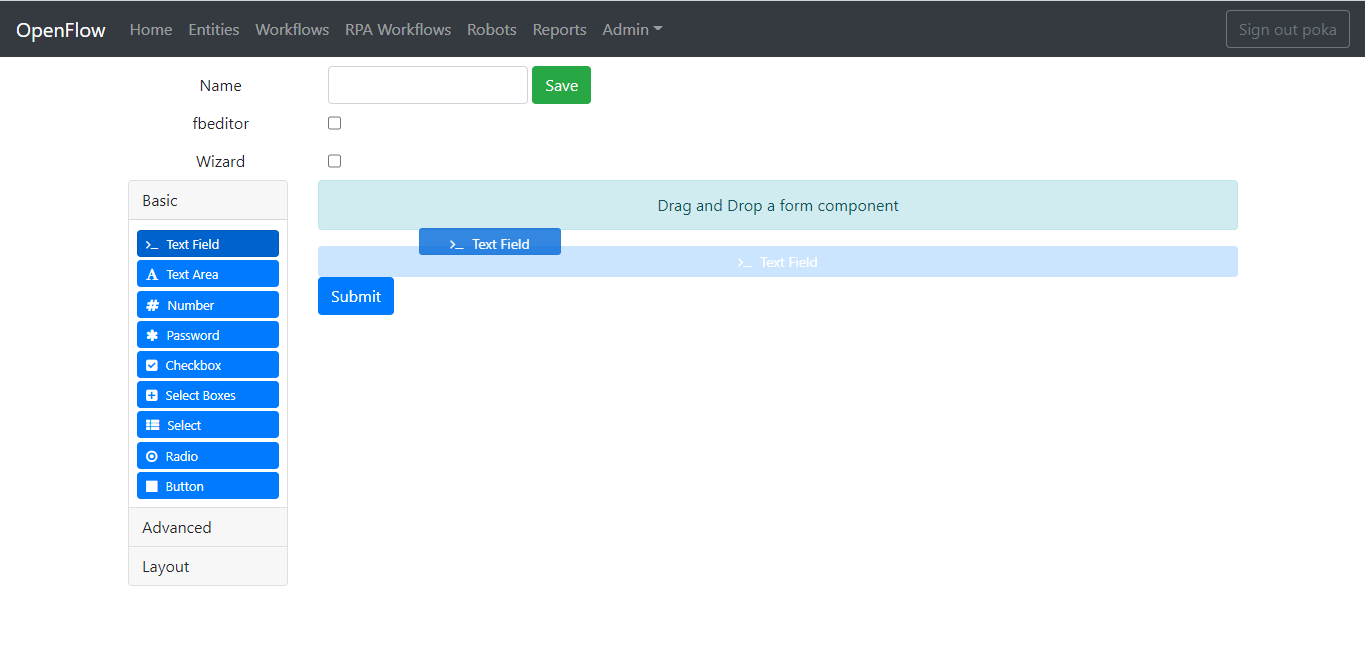
LabelパラメータをPlease enter 'Hello from OpenFlow!' 以下に変更します。
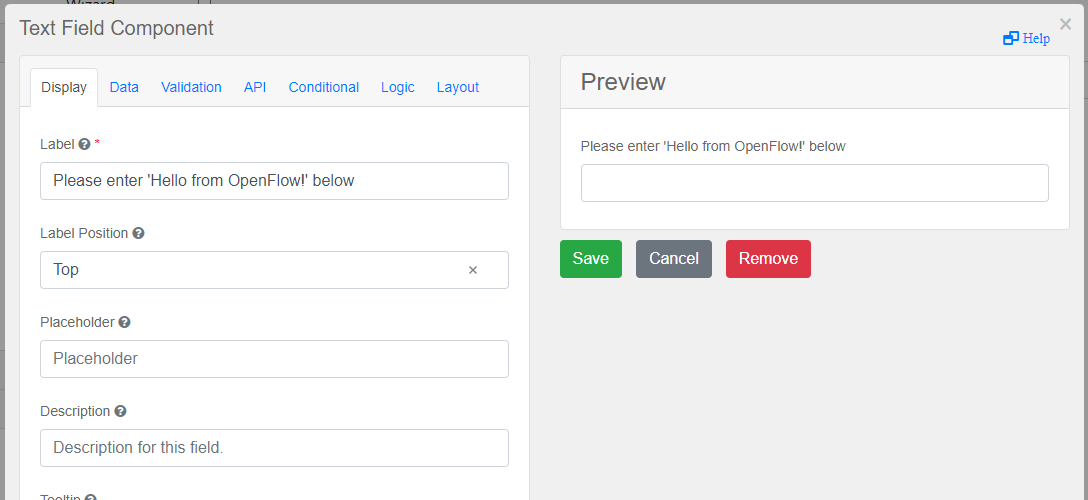
APIタブをクリックし、Property Nameパラメータをhello_from_openflowに変更します。 これがNode-REDに渡される変数になります。
最後に、「保存」ボタンをクリックします。
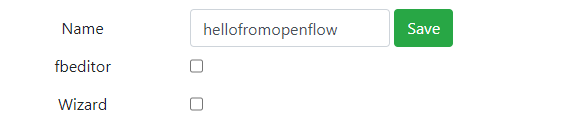
Form名をhellofromopenflowとし、Saveボタンをクリックして保存します。
これで完了です。これでOpenFlowでFormを構成することに成功しました。次のセクションで、Node-REDでどのように設定するかを見ていきましょう。
4.6.1.2. Node-REDのフォームを設定する
ここでは、Node-REDでFormを正しく設定する方法を学習します。
Node-REDインスタンスに移動し、新しいフローを作成し、そのタブで2回クリックして、名前をFormsに変更します。そして、Doneボタンをクリックして保存します。
備考
Node-REDインスタンスの設定方法については、Node-REDへの初回アクセスに進んでください。
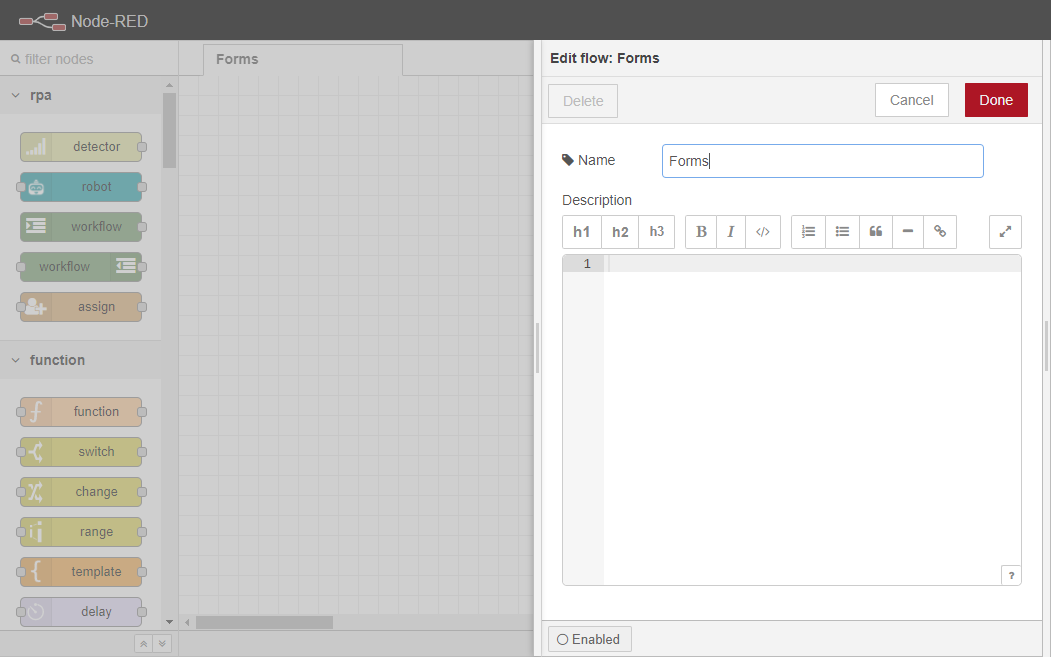
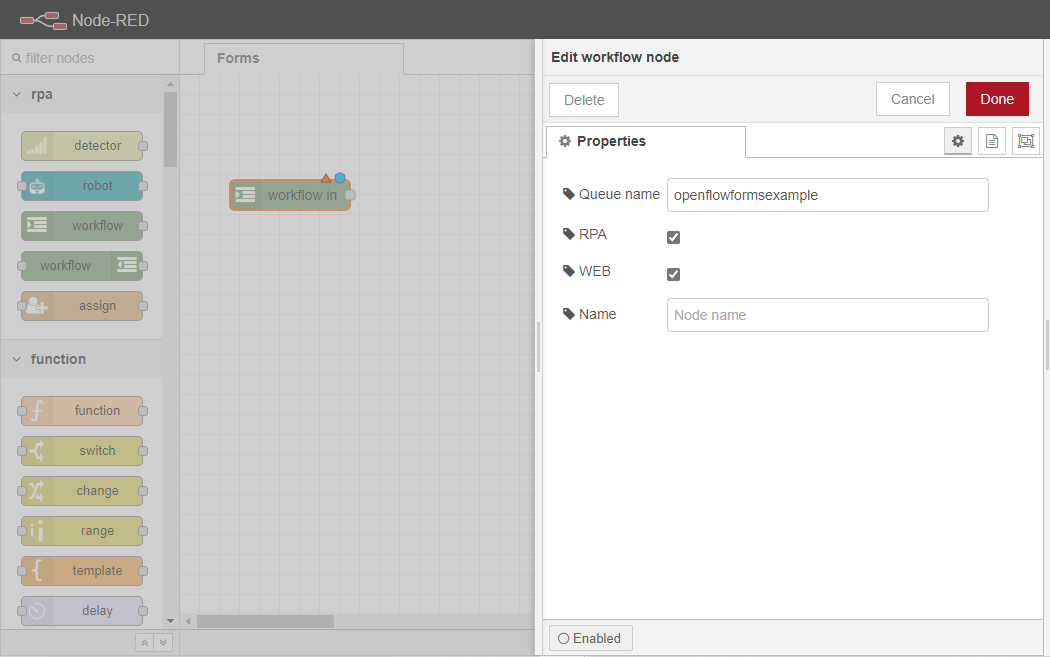
ワークフローインノードをワークスペースにドラッグします。このノードは Form 処理ロジックを実行する実行フローを開始する役割を担います。
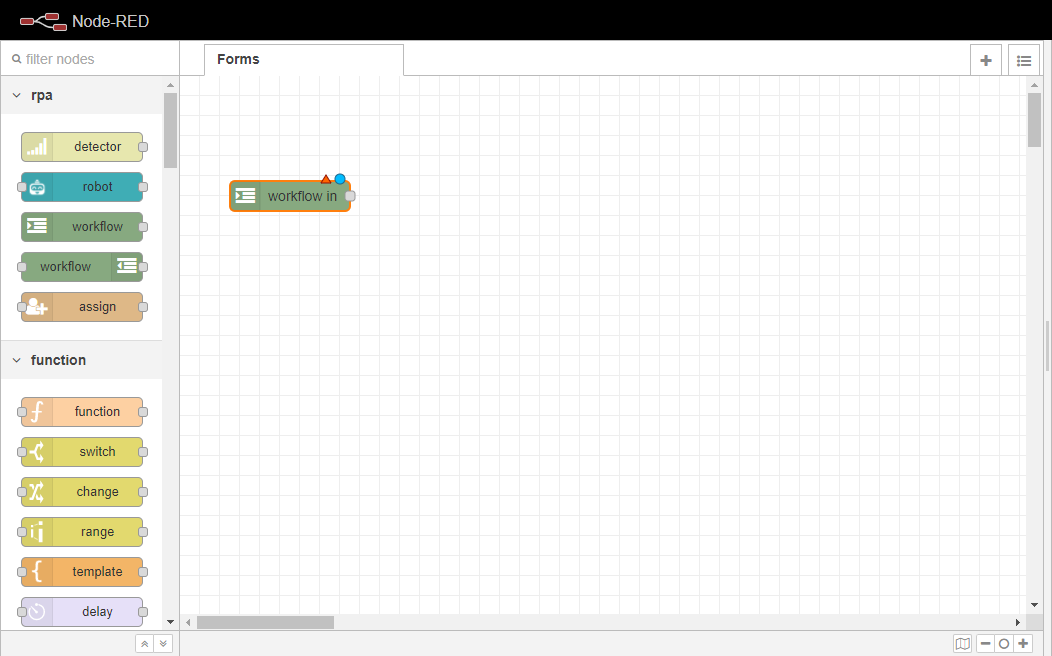
ノード 内の ワークフローを2回クリックし、プロパティタブを開きます。Queue nameを openflowformsexampleに設定し、RPAと WEBの両方のチェックボックスにチェックを入れます。RPAは前項で作成したFormをOpenRPAから呼び出せるようにするためのチェック、WEBはOpenFlowから呼び出せるようにするためのチェックです。また、名前を「OpenFlow Forms Workflow」に変更します。
備考
また、ワークスペース内でノードにフォーカスがある限り、ユーザーはRETURNキーを押してノードのプロパティを編集することができます。
次に、Formから返された変数を処理するロジックを設定します。
ワークスペースにスイッチノードをドラッグし、あらかじめ設定しておいたOpenFlow Forms Workflowノードに配線します。
switchノードを2回クリックして、Propertiesタブを開きます。そのプロパティ・パラメータを msg.payload.hello_from_openflow に設定します。
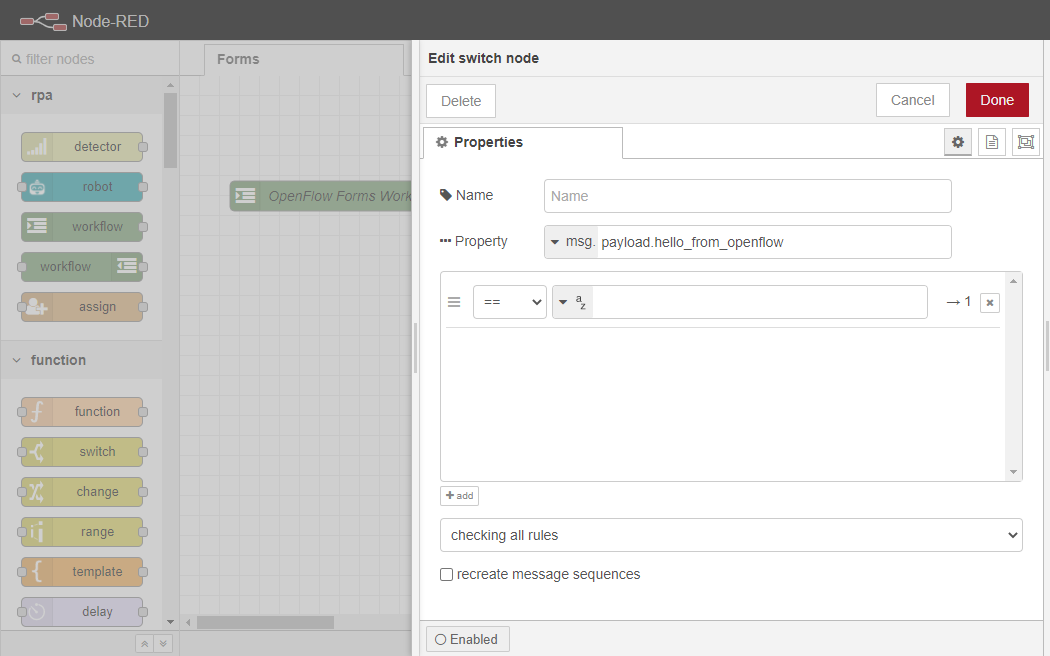
次に、Propertyパラメータのすぐ下にあるパターンマッチングボックスの中で、入力ケースごとに異なるポートを設定することができます。
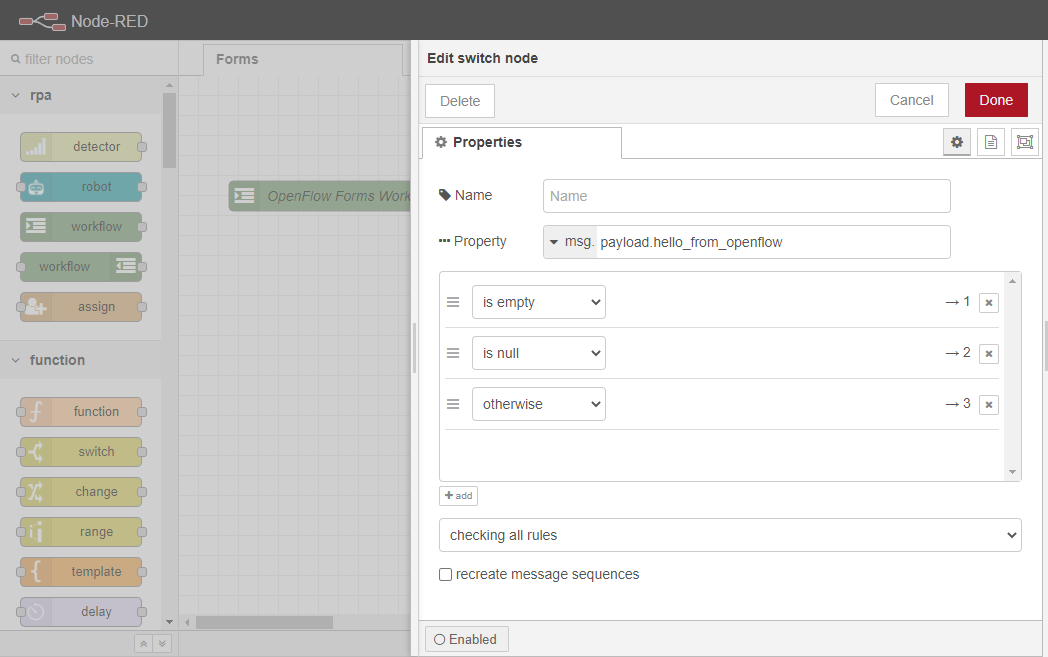
まず、最初のケース(==) をis empty に変更します。 次に、パターンマッチングボックスのすぐ下の+ 追加ボタンをクリックして新しいケースを追加し、is null に設定します。 新しいケースを追加して、other に設定します。 最後に、Doneボタンをクリックしてください。
これは、エンドユーザーが空の入力やNULL入力をしたときに、この実行フローがアイドル状態になり、OpenFlowのホームページでフォームが利用可能になるようにするためのものです。一方、ユーザーが何らかの入力を行った場合、その入力はNode-REDに渡されます。
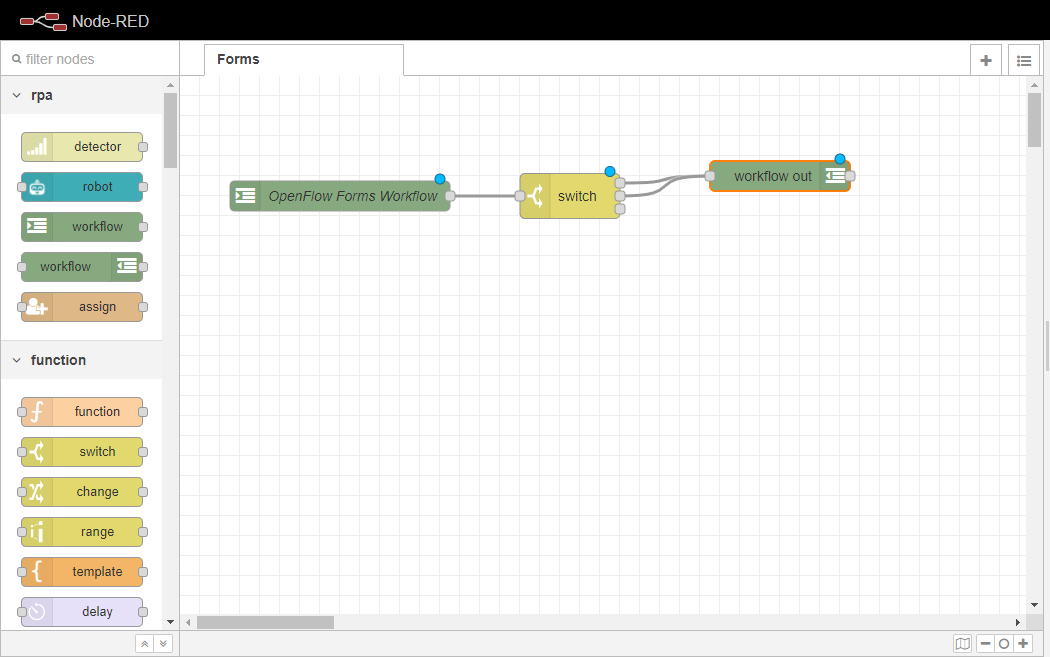
ワークスペースに ワークフローアウトノードをドラッグし、スイッチノードの最初の2つのポートに配線します。 これらのポートは、前のステップで設定したis emptyと is nullのケースにそれぞれ対応しています。つまり、ユーザーが空の入力かNULLの入力をした場合、実行フローはここで終了します。
ワークフローアウトノードを2回クリックし、プロパティタブを開きます。Stateを idleに変更し、Userformを hellofromopenflow(前項で定義したフォーム)に変更します。その後、「Done」ボタンをクリックして変更を保存します。
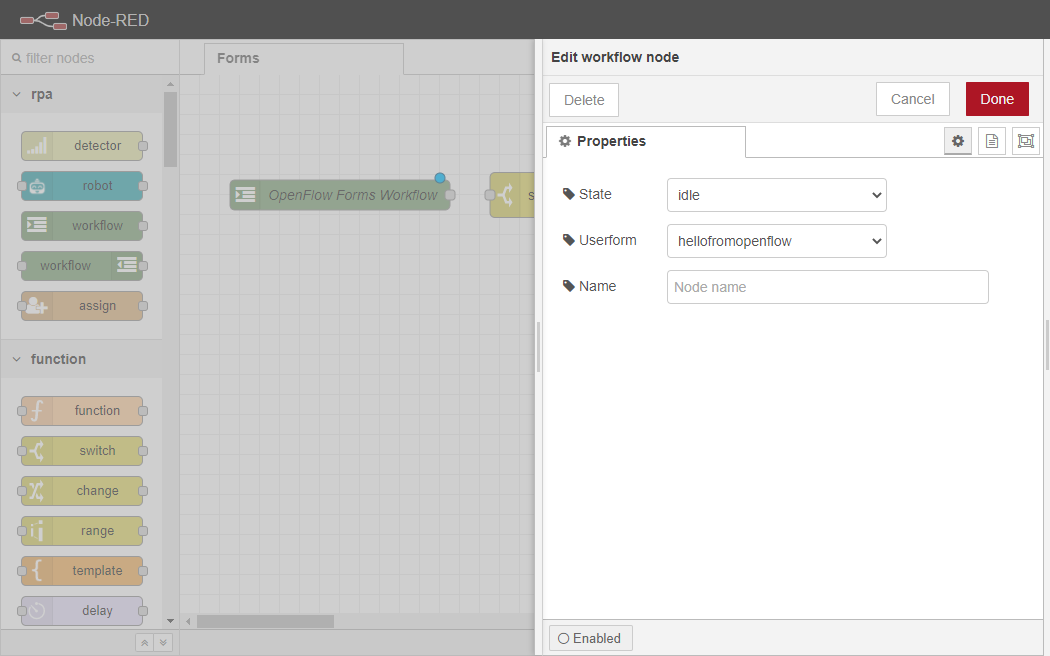
ワークスペースに別の ワークフローノードをドラッグし、スイッチノードの3番目のポート(つまり終了ポート)に配線します。 このポートは、前に設定した他のケースに対応します。
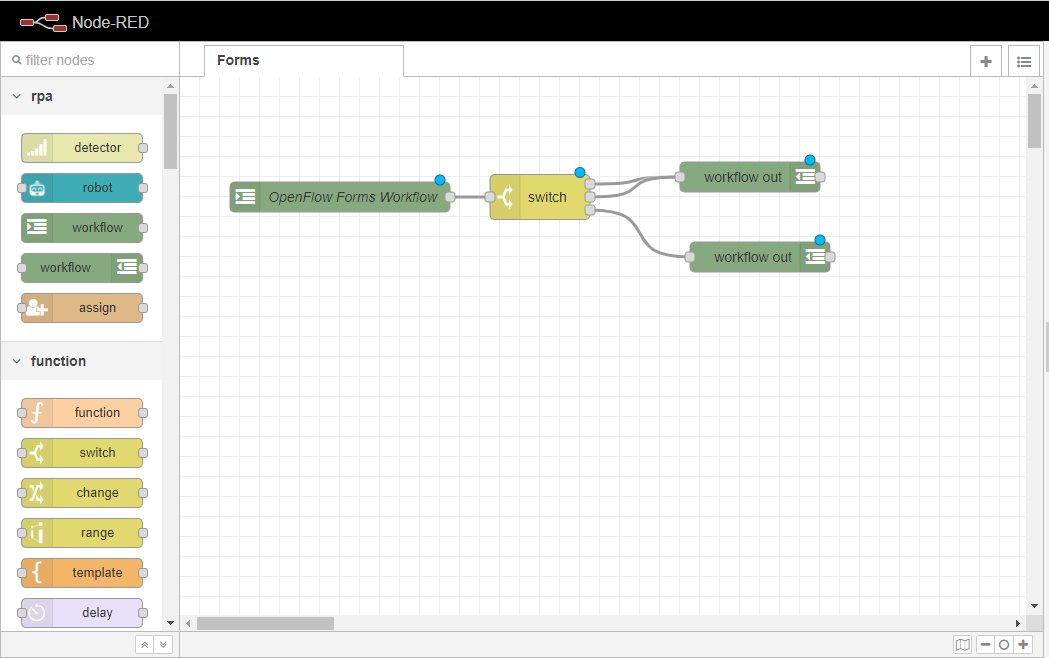
ワークフローアウトノードを2回クリックし、プロパティタブを開きます。Stateを completedに変更し、Userformを hellofromopenflowに変更します。Doneボタンをクリックし、変更を保存します。
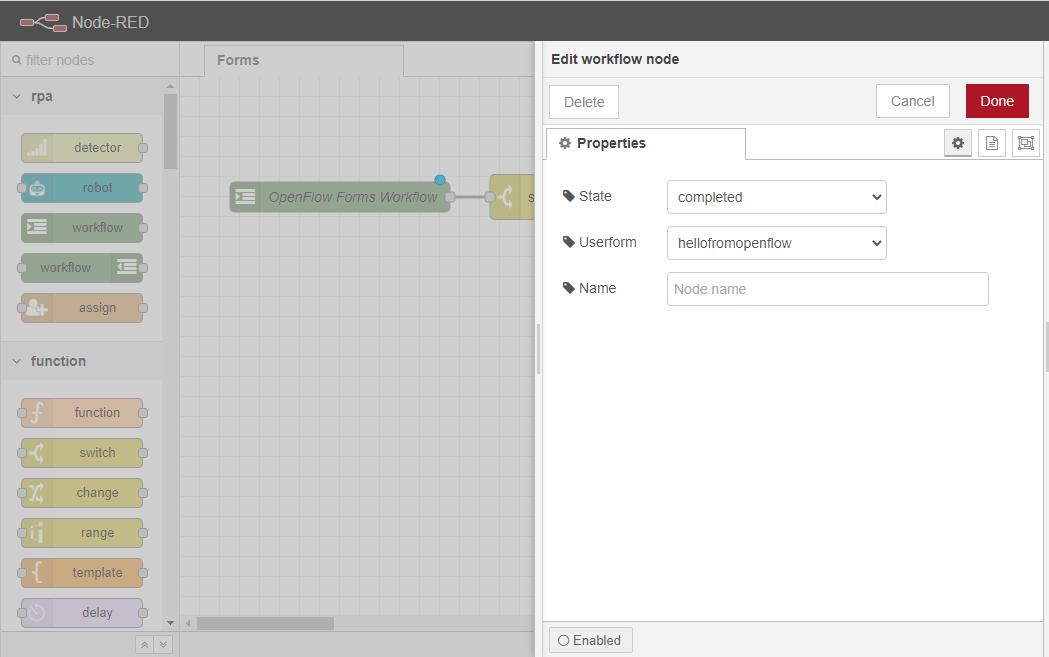
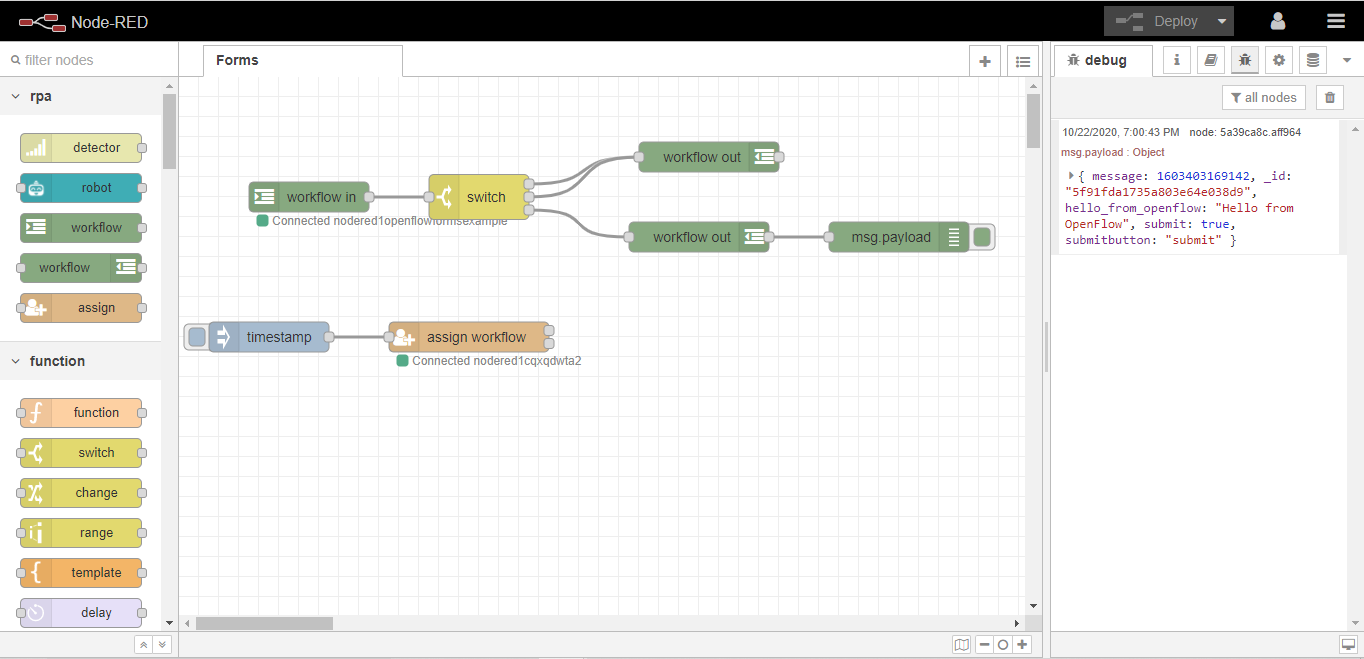
次に、デバッグノードをワークスペースにドラッグし、2番目のワークフロー 出力ノードに配線します。このノードは、ユーザーが Form に渡されるメッセージを見ることができるようにするために使用されます。
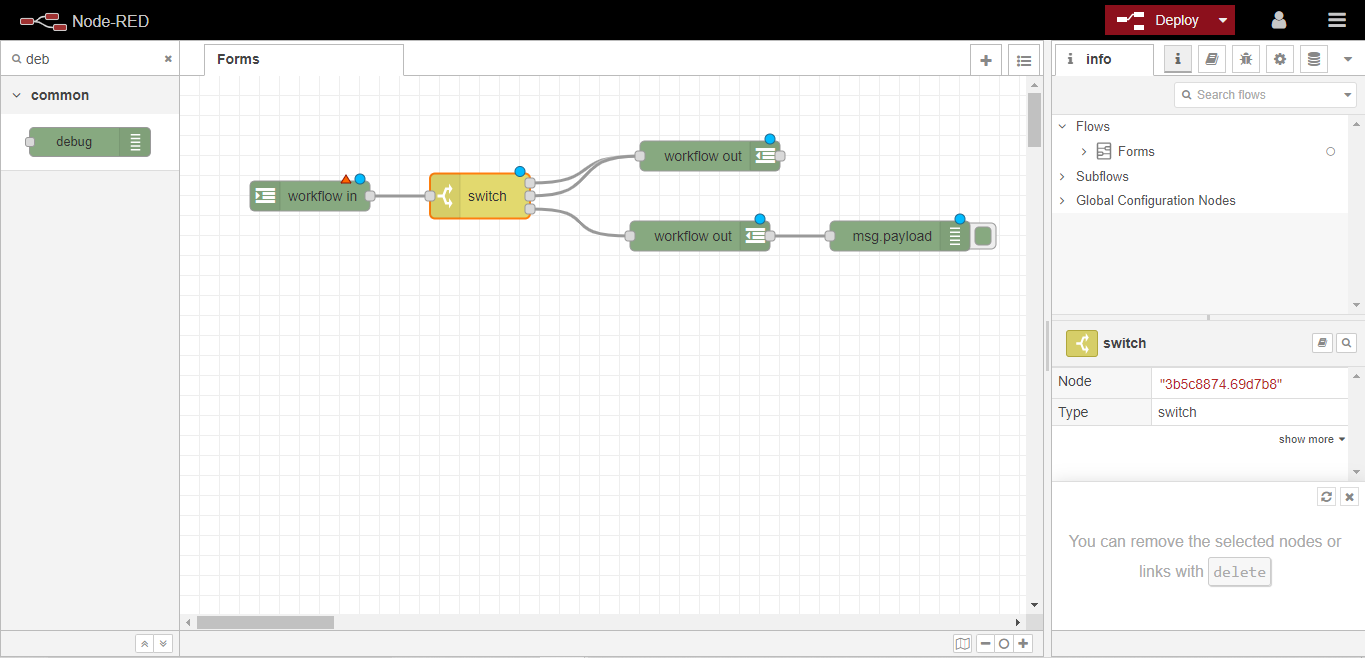
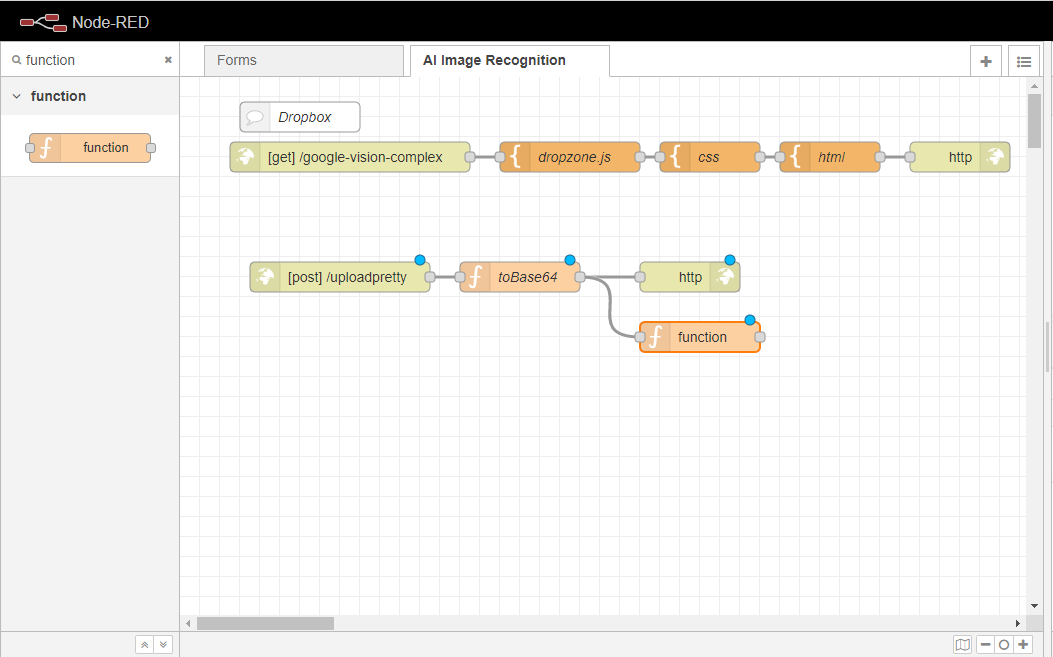
最後に「Deploy」ボタンをクリックすると、Formの設定が完了し、現在のFlowが更新されます。これで、フローは以下の画像のようになります。
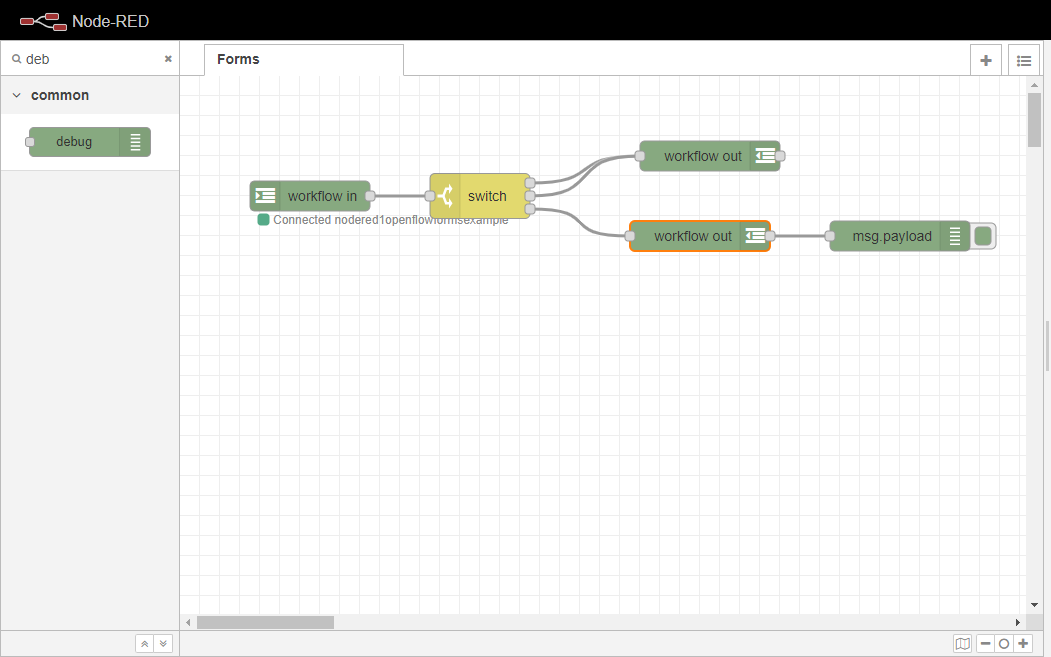
4.6.1.3. フォームの呼び出し
ここでは、Node-REDを使って、作成したFormを呼び出す方法を学びます。
まず、ワークスペースにインジェクトノードをドラッグします。
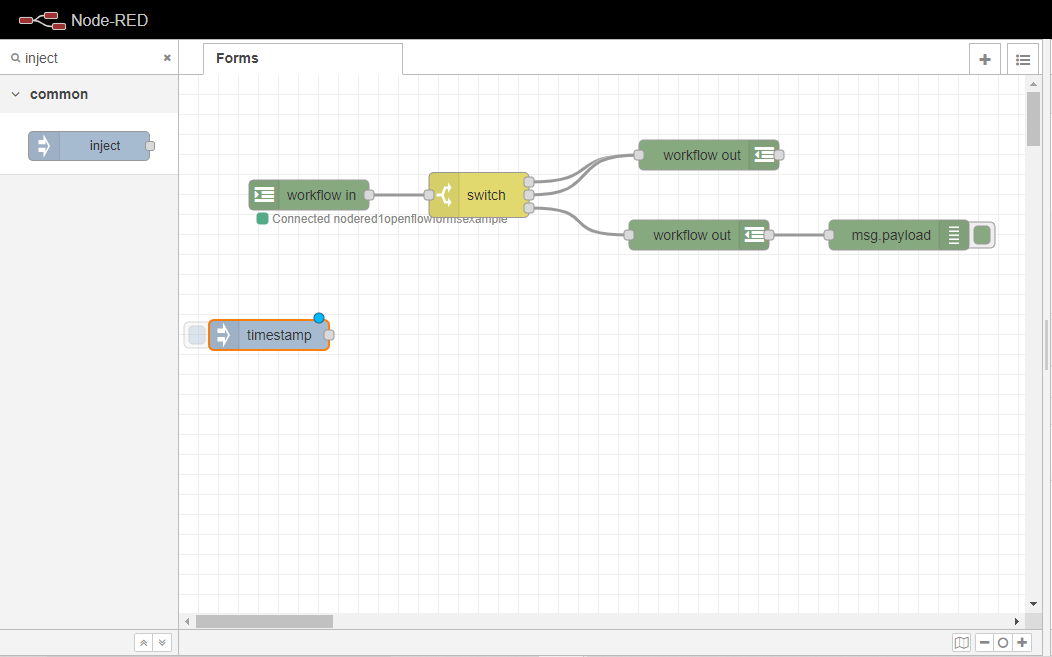
さて、assignノードをワークスペースにドラッグして、先に設定した“inject´`ノードに配線します。
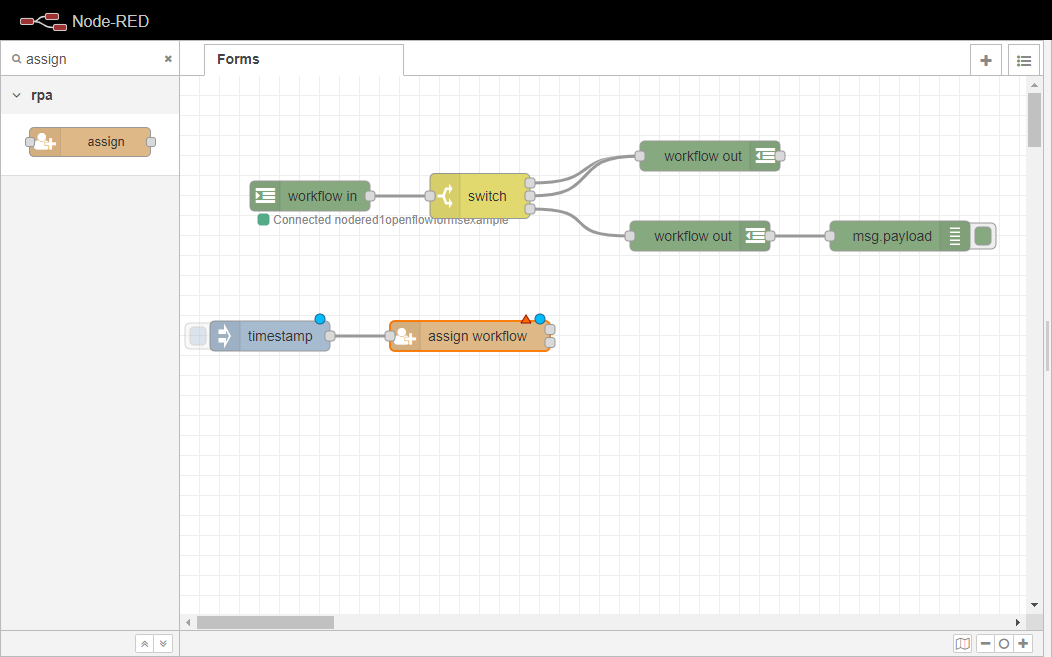
割り当てノードを2回クリックして、「プロパティ」タブを開きます。ワークフローを、前項で設定したopenflowformsexampleワークフローに割 り当てます。ここで、ここで設定したワークフローは、[ワークフロー ]ノードで定義したワークフ ローのキュー 名に対応することを、ユーザーに確認しておいてください。
ここでユーザーは、ワークフローを実行するターゲットを、ロールか特定のユーザーに割り当てることができます。この例では、ユーザを選択することで、ユーザ・ロールに属するユーザは誰でもOpenFlowから呼び出すことができるようになります。
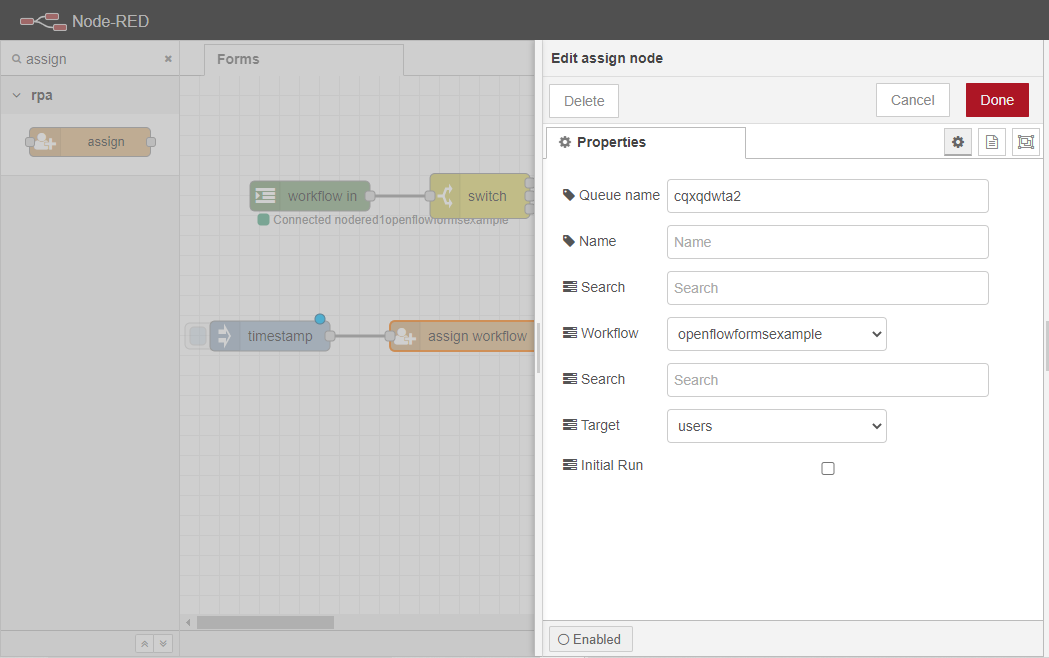
ここで、もう一度[デプロイ]ボタンをクリックして、フローを更新します。
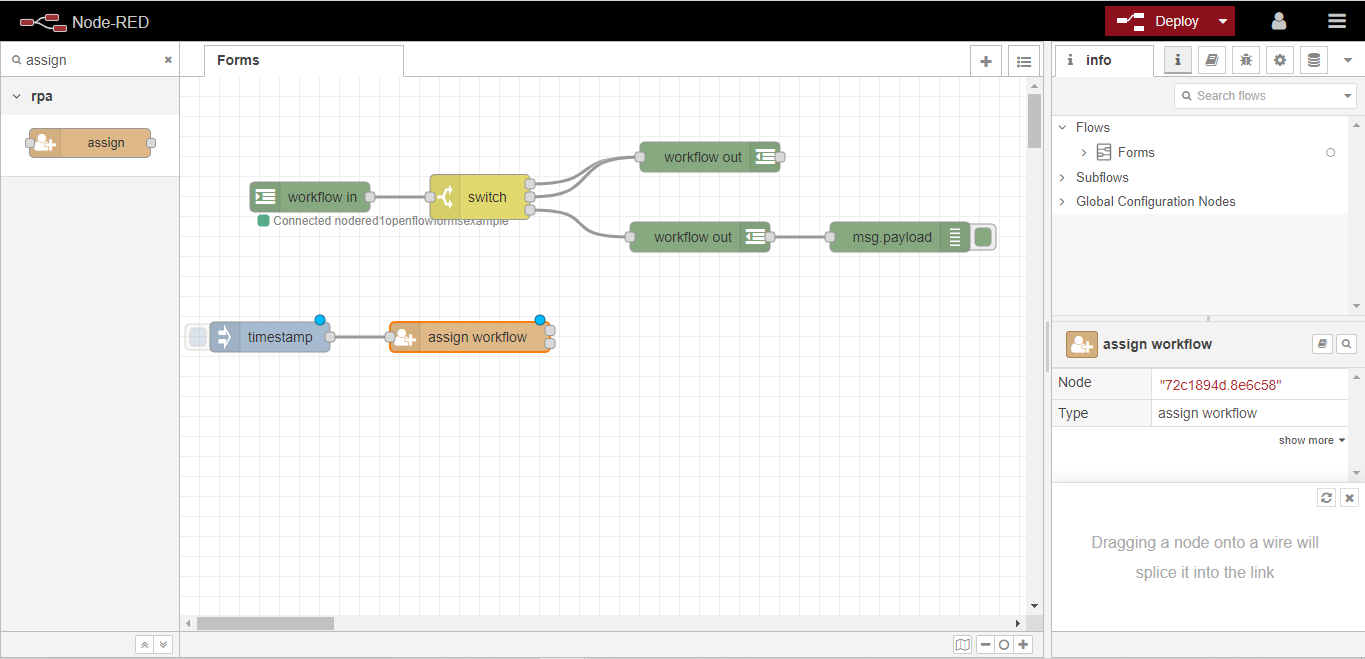
次に、injectノード内のボタンをクリックして、事前に作成したワークフローのインスタンスをロールユーザーに割り当てます。
新しいタブを開いて、OpenFlow のホームページに移動します。先ほど割り当てたワークフローのインスタンスが表示されます。
これで、ユーザはOpenボタンをクリックして、先ほど作成した Form をテストすることができます。テキストフィールドにHello from OpenFlow!と入力し、Submitボタンをクリックします。Node-REDにデバッグメッセージが表示されます。
4.6.2. ダミーインテグレーションOpenRPA-OpenFlow-NodeREDのご紹介です
この例では、メッセージパッシングにOpenRPA、OpenFlow、Node-REDを使用する方法を学習します。
4.6.3. AI画像認識
この例では、Google Cloud Vision API(https://cloud.google.com/vision) に接続して画像の内容を識別するDropzone – Copyright (c) 2012 Matias Meno(https://www.dropzonejs.com/) を含むページをNode-REDで作成する方法を学びます。この例の最終結果は以下のとおりです。ここで興味深いのは、ユーザが最初にAPIキーを適切に設定する必要があることです(https://cloud.google.com/vision/docs/setup)。

Node-REDインスタンスに移動し、新しいフローを作成し、そのタブで2回クリックしてAI Image Recognitionに名前を変更します。 その後、Doneボタンをクリックして保存します。
これでフローが作成されたので、ユーザーはページを提供するHTTPエンドポイントの作成に進むことができます。Deploy]ボタンをクリックして、変更を保存することを忘れないでください。
4.6.3.1. テンプレートとHTTPエンドポイントによるページの提供
このセクションでは、エンドユーザーの入り口となるページを作成する方法を学びます。エンドユーザーは、作成されたページにWindowsの ファイルダイアログから画像をドロップしたり選択したりすることができるようになります。
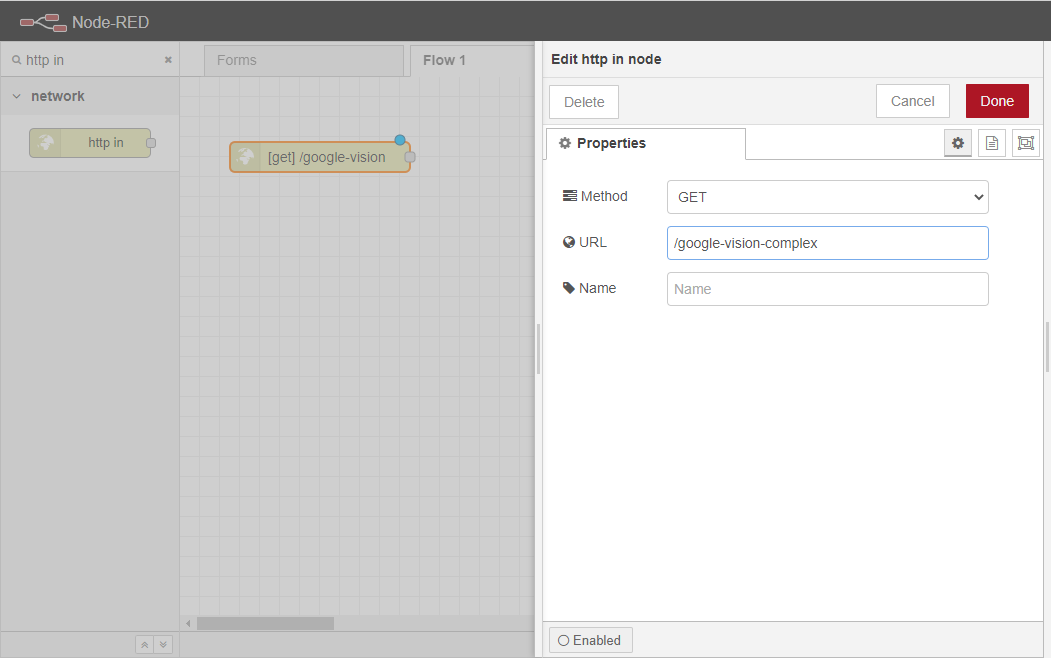
http inノードをワークスペースにドラッグします。

http inノードを2回クリックし、プロパティタブを開きます。
ユーザはそのURLを好きなサブロケーションに設定することができますが、簡単のために/google-vision-complex と設定します。 これは、プロパティの権限を持つエンドユーザは、Node-REDインスタンスのURLと上記のサブロケーション、つまりpaulo.app.openiap.io/google-vision-complex からページにアクセスすることができるということです。 Node-REDインスタンスを設定する方法について分からない場合はNode-RED に初めてアクセスする方法を参考にしてみてください。
このサブロケーションをどこかに保存してください。次のセクションで、ユーザーはこのサブロケーションを指すウェブソケットをセットアップするからです
URLを設定した後、ユーザーはDoneボタンをクリックして、ノードの設定を終了することができます。
備考
また、ワークスペース内でノードにフォーカスがある限り、ユーザーはRETURNキーを押してノードのプロパティを編集することができます。
備考
Node-REDインスタンスの設定方法については、Node-REDへの初回アクセスに進んでください。
テンプレートノードをワークスペースにドラッグして、http inノードに配線します。
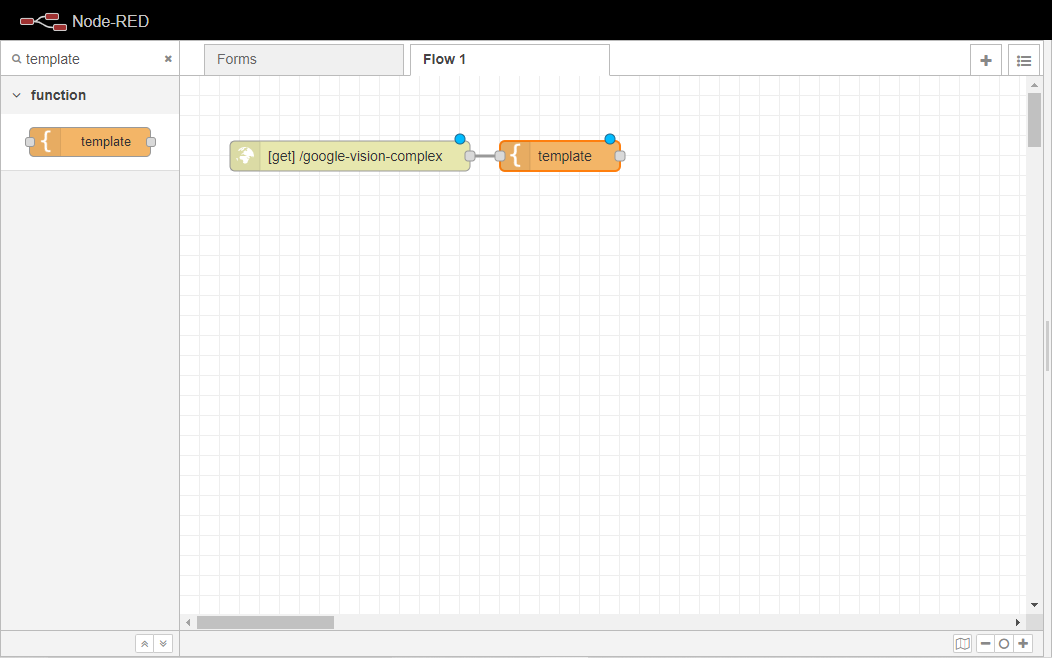
テンプレートノードを2回クリックして、そのプロパティタブを開きます。
まず、ノードの名前をdropzone.jsに変更します。
次に、そのプロパティを msg.dropzonejsに、シンタックス ハイライトを Javascript に変更します。
最後に、DropzoneJS for AI Image Recognition(https://gist.github.com/syrilae/945838275bf729fb568d91dd63147706)に含まれる生のコードをTemplateボックスに貼り付けてください。このコードは、Dropbox内に画像がドロップされたときの画像処理とAPIへのアップロードのロジックを担っています。
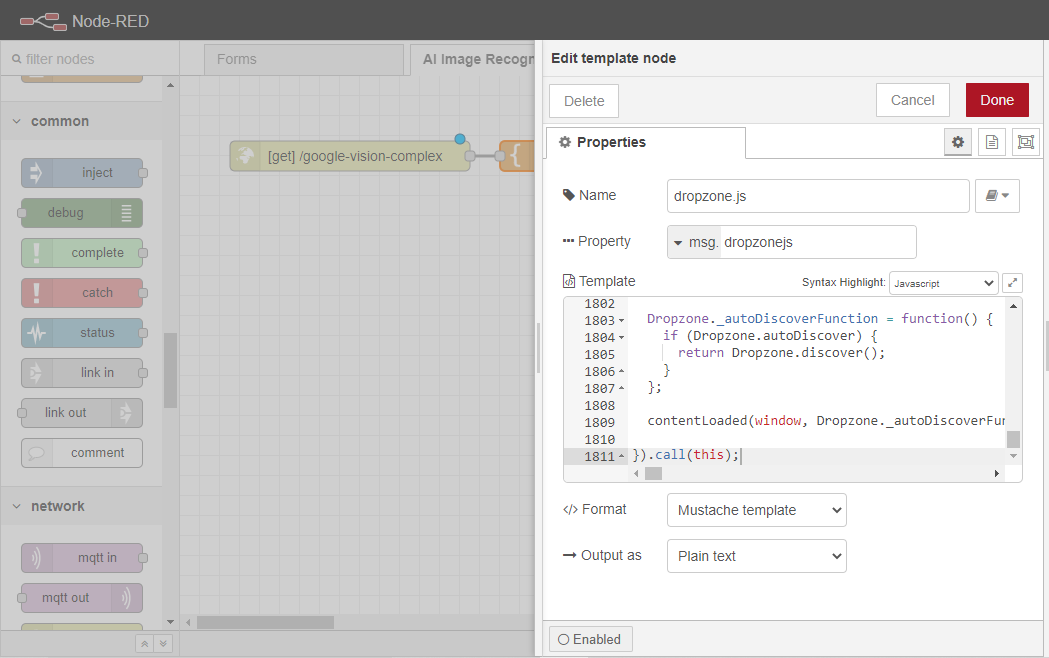
次に、別のテンプレートノードをワークスペースにドラッグして、上で作成したばかりのdropzone.jsノードに配線します。このノードは、カスタムCSS でDropboxをスタイリングする役割を果たします。
新しく追加されたテンプレートノードを2回クリックして、そのプロパティタブを開きます。
ノードの名前をcssに変更します。
プロパティを msg.cssに、シンタックス ハイライトを CSS に変更します。
ここで、DropzoneJS CSS for AI Image Recognition(https://gist.github.com/syrilae/dde9fcbbdcfe6a4ff4750a2359963d7f)に含まれる生のコードをTemplateボックスに貼り付けてください。このコードは、Dropboxページのスタイリングを担当します。
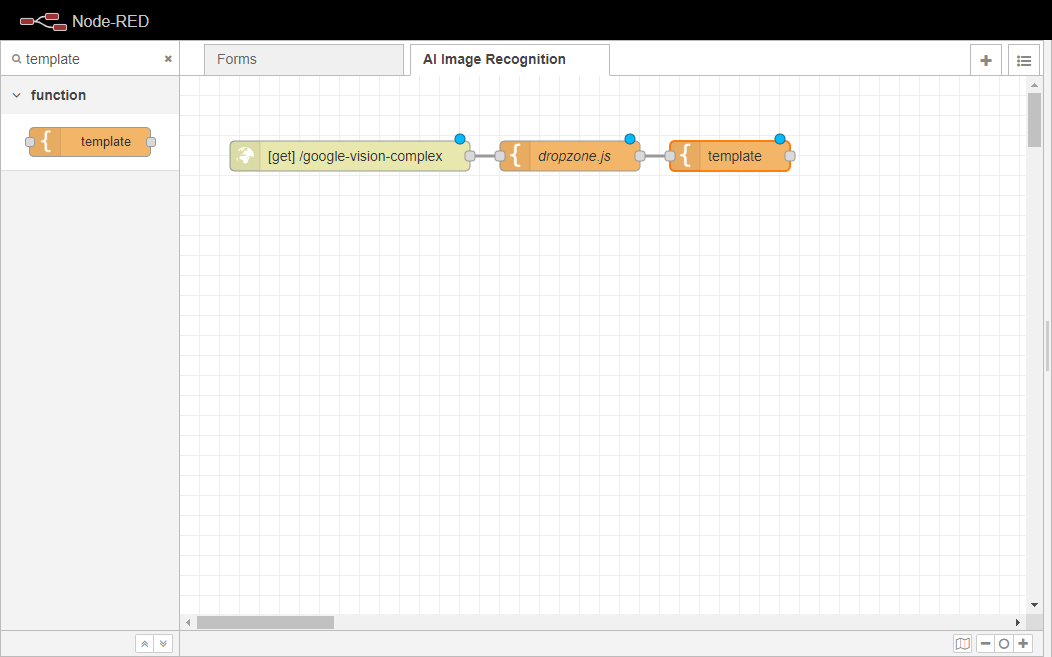
別のテンプレートノードをワークスペースにドラッグして、上で作成したばかりのcss`ノードに配線します。このノードの役割は、ページの背後にあるHTMLコードになります。基本的に、これまでに追加されたすべてのものを構造化します。
このテンプレートノードを2回クリックすると、そのプロパティタブが開きます。
ノードの名前をhtmlに変更します。
以下のコードをテンプレートボックス内に貼り付けてください。
<script> {{{dropzonejs}}}</script><style> {{{css}}}</style><script> // "myAwesomeDropzone" is the camelized version of the HTML element's ID Dropzone.options.myDropzone = { paramName: "myFile", // The name that will be used to transfer the file maxFilesize: 2, // MB accept: function(file, done) { if (file.name == "justinbieber.jpg") { done("Naha, you don't."); } else { done(); } } };</script><h1>Google Vision API - Upload a file here:</h1><body onload="wsConnect();" onunload="ws.disconnect();"> <form action="/uploadpretty" class="dropzone" method="post" enctype="multipart/form-data" id="my-dropzone"> <div class="fallback"> <input name="myFile" type="file" /> <input type="submit" value="Submit"> </div> </form> <font face="Arial"> <pre id="messages"></pre> <hr/> </font> <img src='https://bpatechnologies.com/images/logo_footer.png'></body>
最初のMustache(https://mustache.github.io/mustache.5.html)、すなわち{{dropzonejs}}は、http innodeによって作成されたエンドポイントに渡されるdropzone.jsノードの実行ロジックをページに追加する役割を担っています。
2番目のヒゲは、この同じページにCSSのスタイルを追加する役割を担っています。また、justinbieber.jpgという名前のファイルをアップロードできないようにするためのダジャレ(イースターエッグ)も追加されていますが、この部分は削除してもかまいません。
残りのコードは、Google Vision API - Upload a file hereを含む<h1>ラベルを表示し、ウェブサービスへの接続とフォールバック 実行のためのロジックを設定します。
http 応答ノードをワークスペースにドラッグし、先に作成したテンプレートノードに配線します。
最後に、最後のステップとして。Node-REDで自分のFlowにコメントをつける方法を学習します。
コメントノードをワークスペースにドラッグして、http inノードのすぐ上に挿入します。
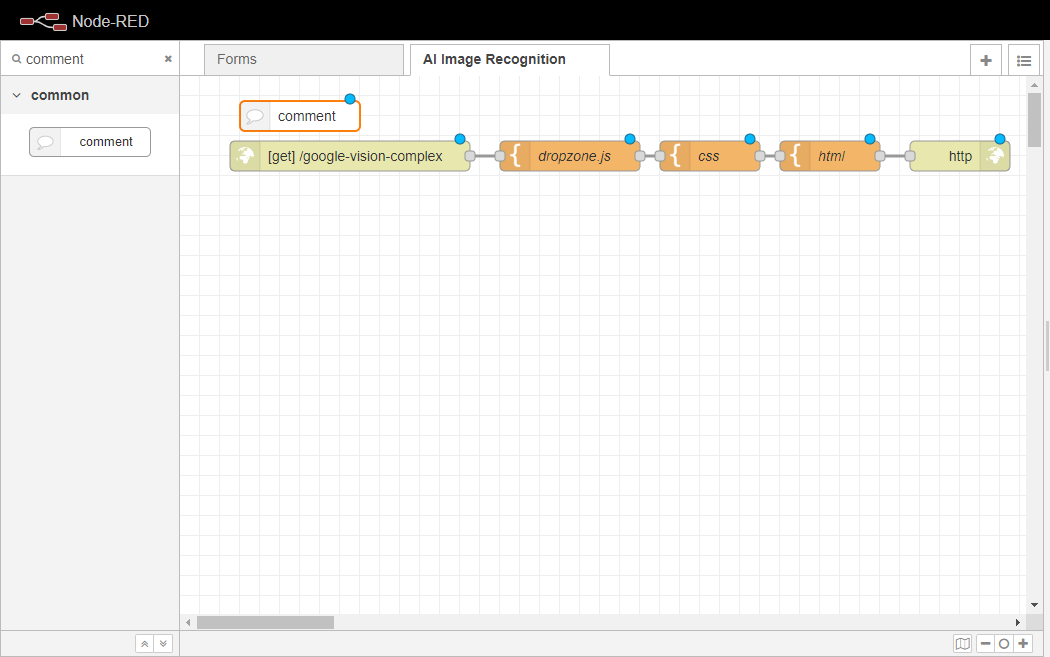
コメントノードを2回クリックし、プロパティタブを開きます。
ノードの名前をDropboxに変更します。
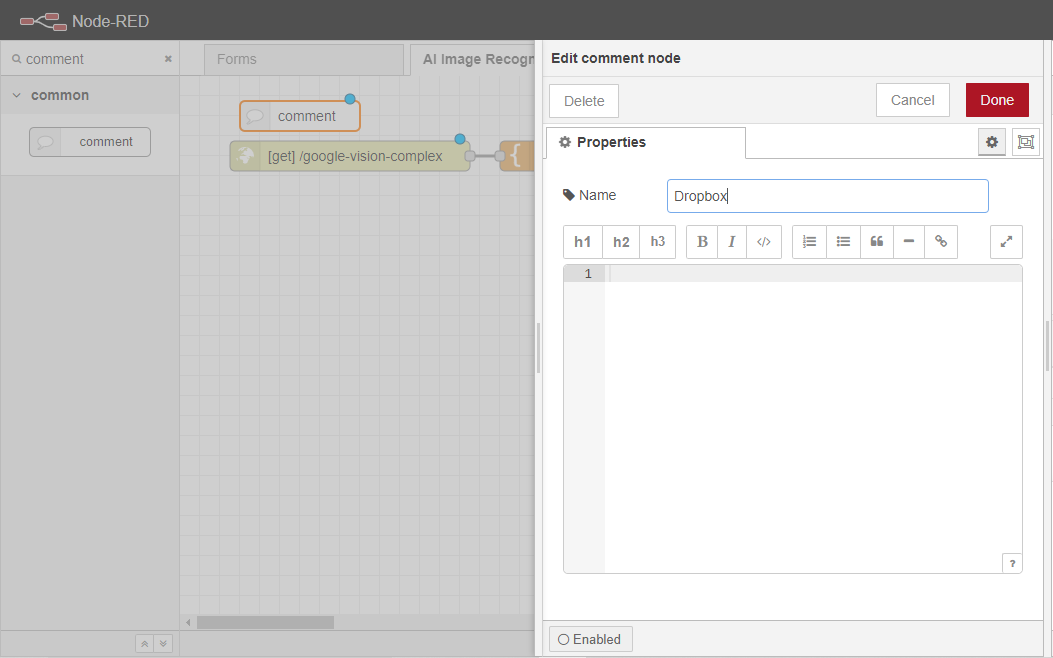
最後に、「デプロイ」ボタンをクリックして、変更をコミットします。
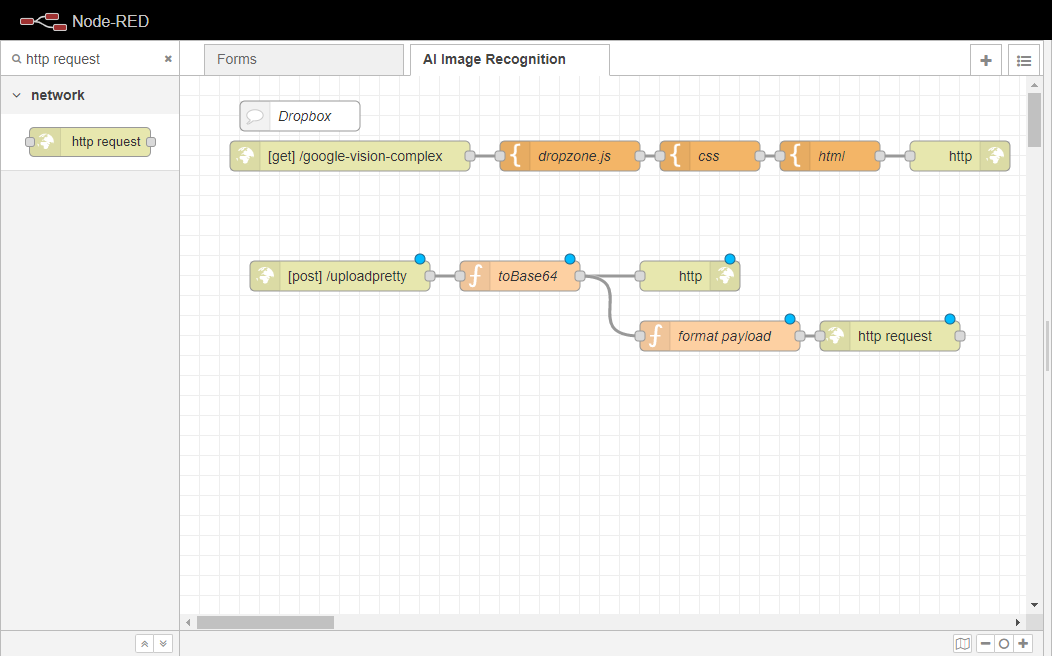
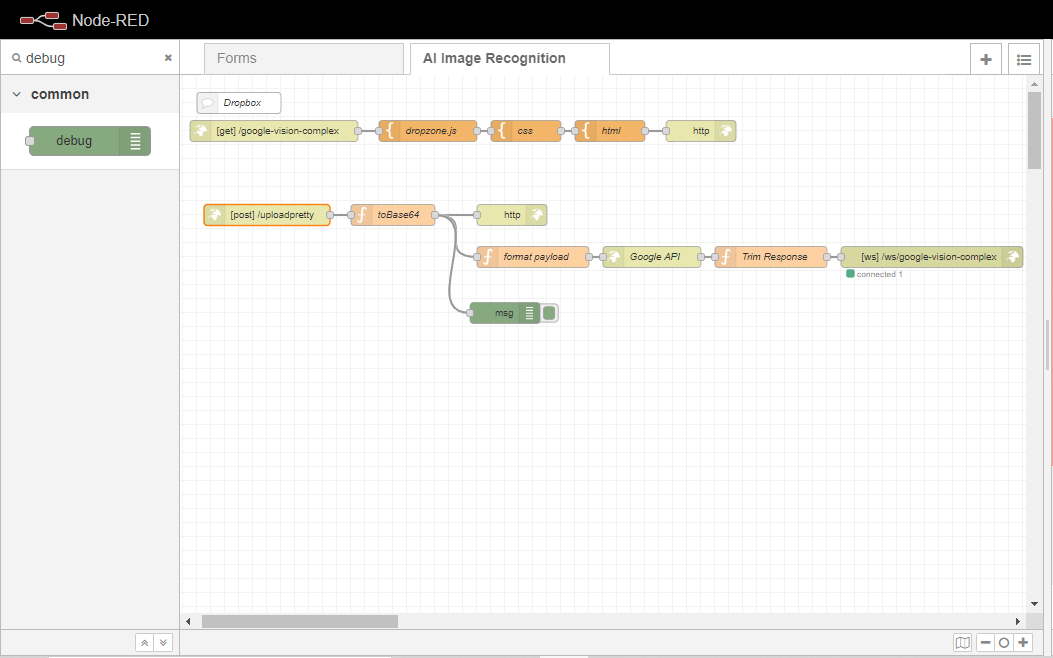
以上です。あなたは、このフローの例の最初の部分を終了しました。あなたのフローは、以下の画像のようになるはずです。
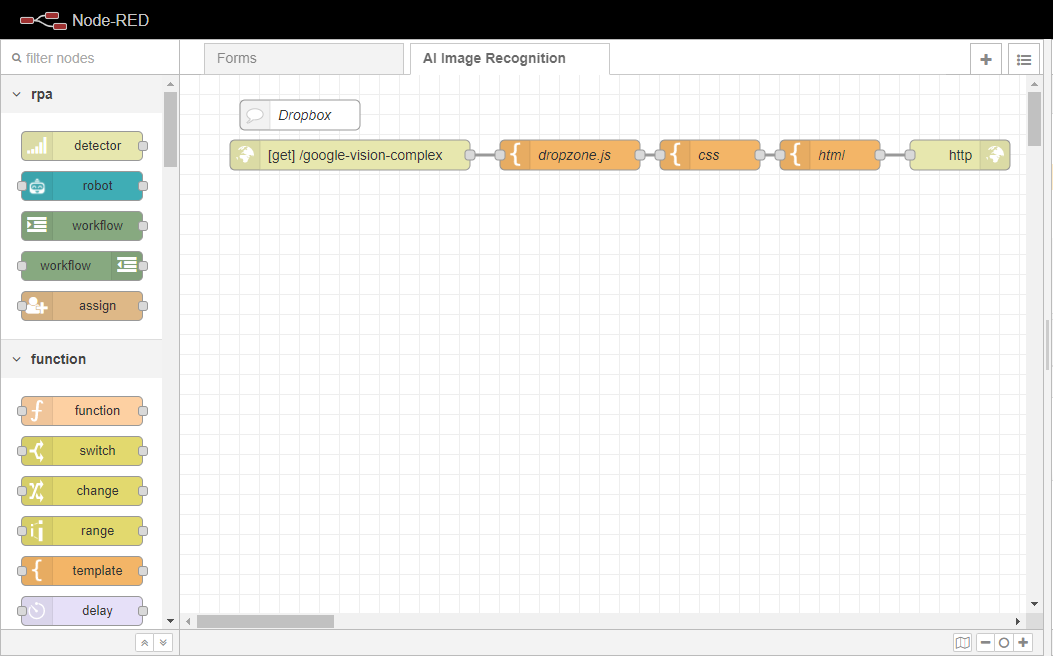
Dropboxページの設定が終わったので、Google Cloud Vision API(https://cloud.google.com/vision)にファイルをアップロードするための処理ロジックを実装します。
4.6.3.2. Google Cloudのビジョン処理ロジック
ここでは、エンドユーザーから取得する画像をGoogle Cloud Vision API(https://cloud.google.com/vision)にアップロードし、データを受信するロジックを実装する方法を学習します。
まず、http inノードをFlowにドラッグします。
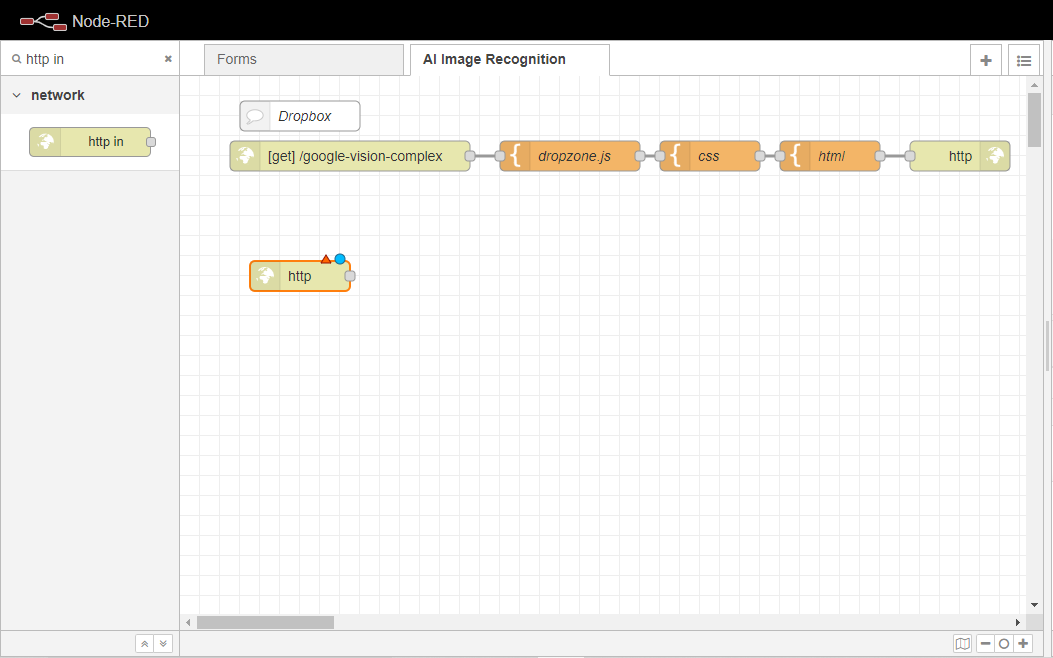
http inノードを2回クリックし、プロパティタブを開きます。
メソッドプロパティを POSTに設定する。
前のセクションのhtmlで定義したフォームの actionプロパティがこのサブロケーションに設定されているので、ユーザーはURLを/uploadpretty に設定する必要があります。
また、Accept file uploads?チェックボックスをチェックすると、ウェブソケットにファイルをアップロードすることができなくなります。
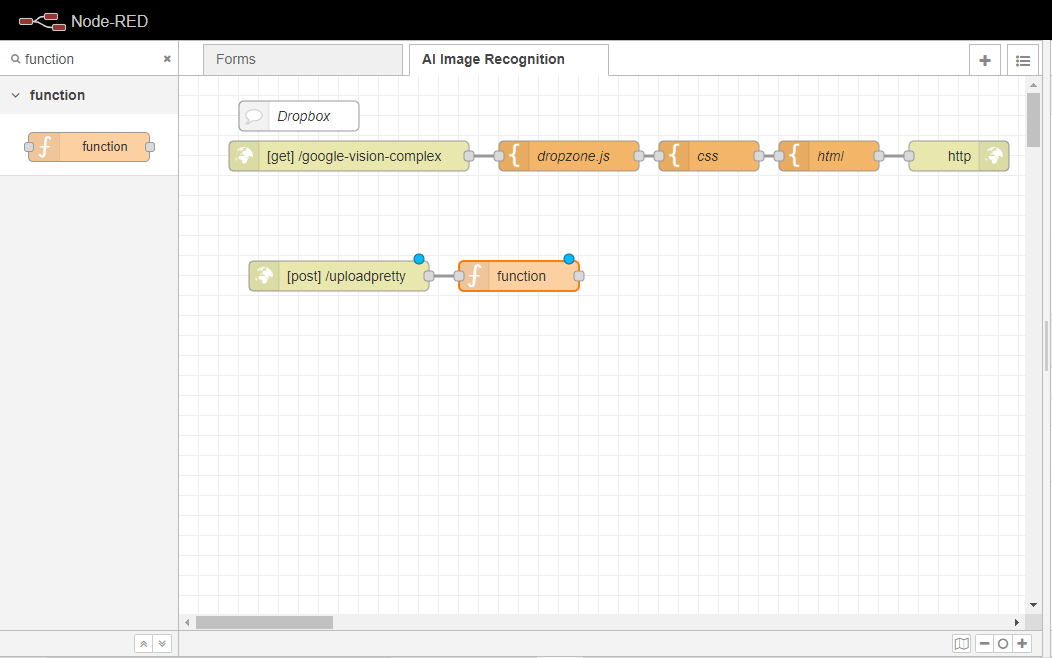
関数ノードをワークスペースにドラッグし、[post] /uploadprettyノードに配線します。このノードは、Google Cloud Vision API(https://cloud.google.com/vision) にアップロードできるように、アップロードされた画像をBase64(https://developer.mozilla.org/en-US/docs/Glossary/Base64) に変換する役割を担います。
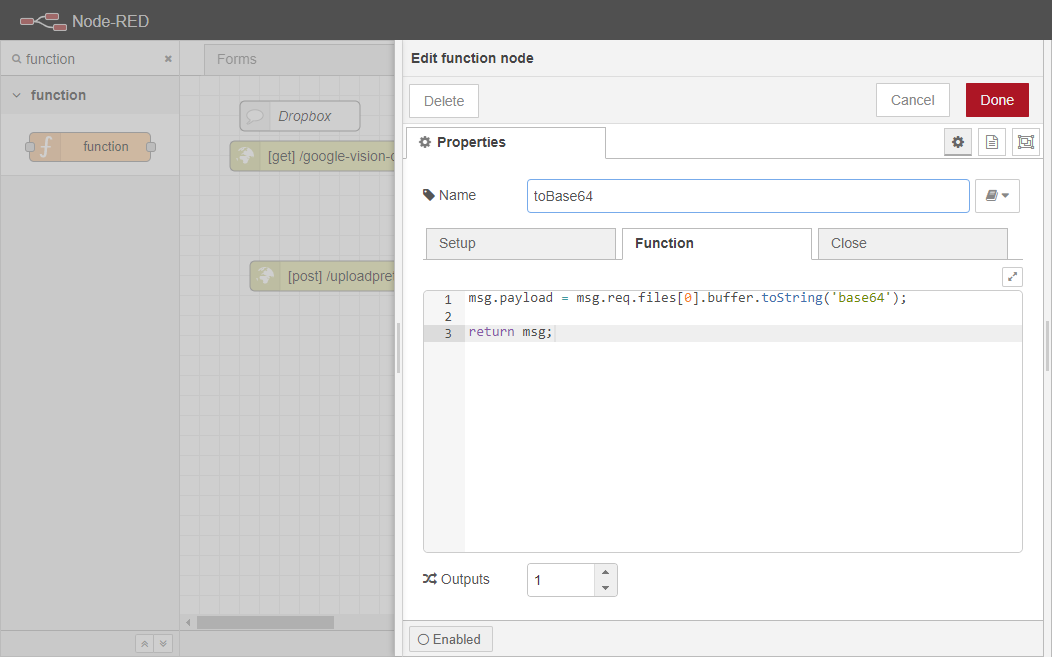
関数ノードを2回クリックして、そのプロパティタブを開きます。
toBase64にリネームしてください。
関数]ボックスに次のコードを貼り付けます。
msg.payload = msg.req.files[0].buffer.toString('base64');return msg;
このコードは、アップロードされた最初の画像を収集し、エンコードされたBase64文字列にバッファリングする役割を担っています。
これで実行フローは3つのブランチに分かれることになる。
最初のブランチは、エンドユーザーのクライアントに、サブミットアクションが成功したかどうかを示すステータス メッセージを 返す責任を負います。
2番目のブランチは、ペイロードをフォーマットし、画像をGoogle Cloud Vision API(https://cloud.google.com/vision)にアップロードし、前のセクションで作成したページを更新します。後者の部分は、 ウェブソケットアウトノードを作成することによって行われます。
3つ目のブランチは、エンドポイントに渡されたすべてのリクエストをリスニングし、それをデバッグメッセージに変えます。
なお、これらのブランチはすべて、エンドユーザーがウェブサイトに画像をアップロードする際に実行されます。
まず、ワークスペースにhttp responseノードをドラッグして、toBase64ノードに配線します。
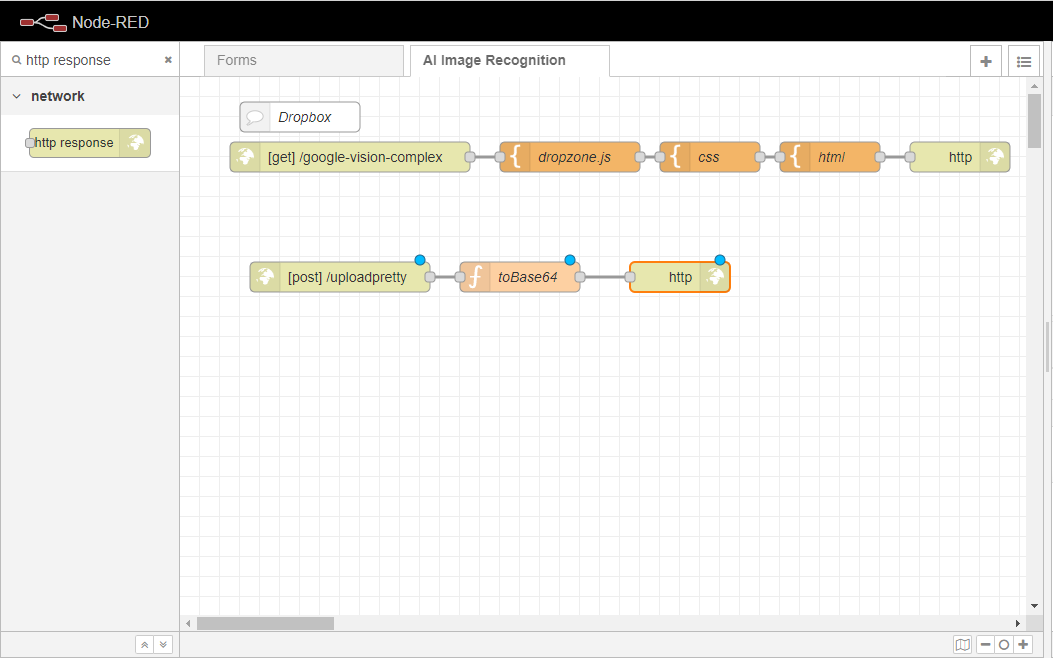
ここで、関数ノードをワークスペースにドラッグし、同様にtoBase64ノードに配線します。
フォーマットペイロードに改名する。
関数]ボックスに、次のコードを貼り付けます。
msg.image64 = msg.payload;msg.payload = { requests: [ { image: { content: msg.payload }, features: [ { maxResults: 5, type: "LABEL_DETECTION" } ] } ]}return msg;
このコードは、画像をmsg.payload変数に渡すことと、検出されたLABEL_DETECTION 機能(https://cloud.google.com/vision/docs/labels) の数を5件の結果に制限することを担当します。
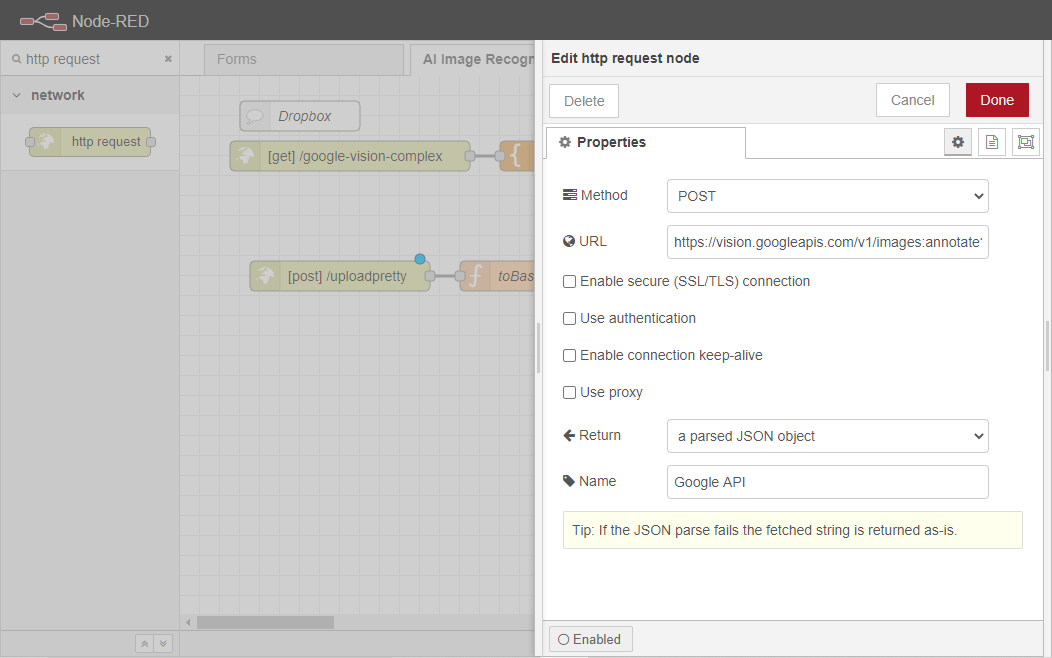
http requestノードをワークスペースにドラッグして、format payloadノードに配線します。このノードは、Google Cloud Vision API(https://cloud.google.com/vision) にペイロードを接続して送信し、API から取得したデータを担当するJSON オブジェクトを返す役割を担います。
http リクエストノードを2回クリックし、プロパティタブを開きます。
メソッドを POSTに設定します。
URLを https://vision.googleapis.com/v1/images:annotate?key={KEY} と設定します。{KEY}はGoogle Cloud Vision API Key(https://cloud.google.com/vision/docs/setup) に対応します。
変更 パースされた JSON オブジェクトに 戻ります 。
Google APIにリネームしてください。
別の関数ノードをワークスペースにドラッグして、Google APIノードに配線する。このノードは、Google Cloud Vision API(https://cloud.google.com/vision) から返されたデータを戻り値の配列に渡し、シリアライズされた JSON 文字列に変換して、websocket outノードに渡せるようにする役割を果たします。これによって、ユーザーが画像をアップロードすると、ページが自動的にアップロードされるようになります。
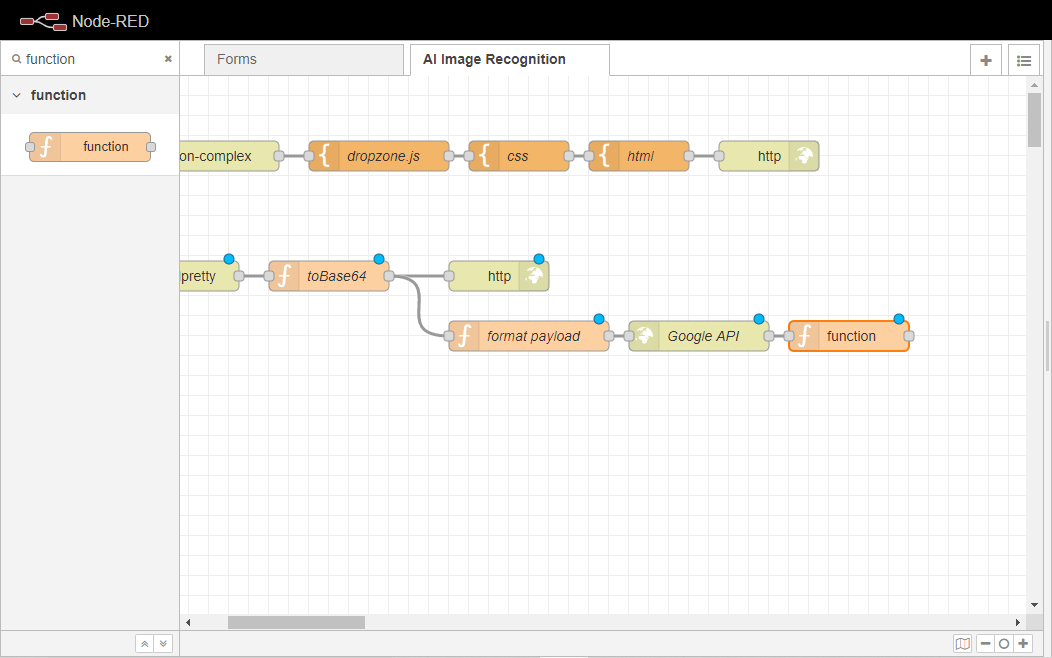
関数ノードを2回クリックして、そのプロパティタブを開きます。
ノードの名前を「Trim Response」に変更します。
関数]ボックスに次のコードを貼り付けます。
var retArray = []for( var i in msg.payload.responses[0].labelAnnotations ){ let desc = msg.payload.responses[0].labelAnnotations[i].description let score = msg.payload.responses[0].labelAnnotations[i].score let thisObj = { desc: desc, score: score } retArray.push(thisObj)}msg.payload = { result: retArray, resultJSON: JSON.stringify(retArray, null, '\t')}msg.payload = msg.payload.resultJSONreturn msg
ワークスペースに ウェブソケットアウトノードをドラッグし、それを トリムレスポンスノードに配線します。このノードは、イベント・リスナーを設定する役割を果たし、そのリスナーは
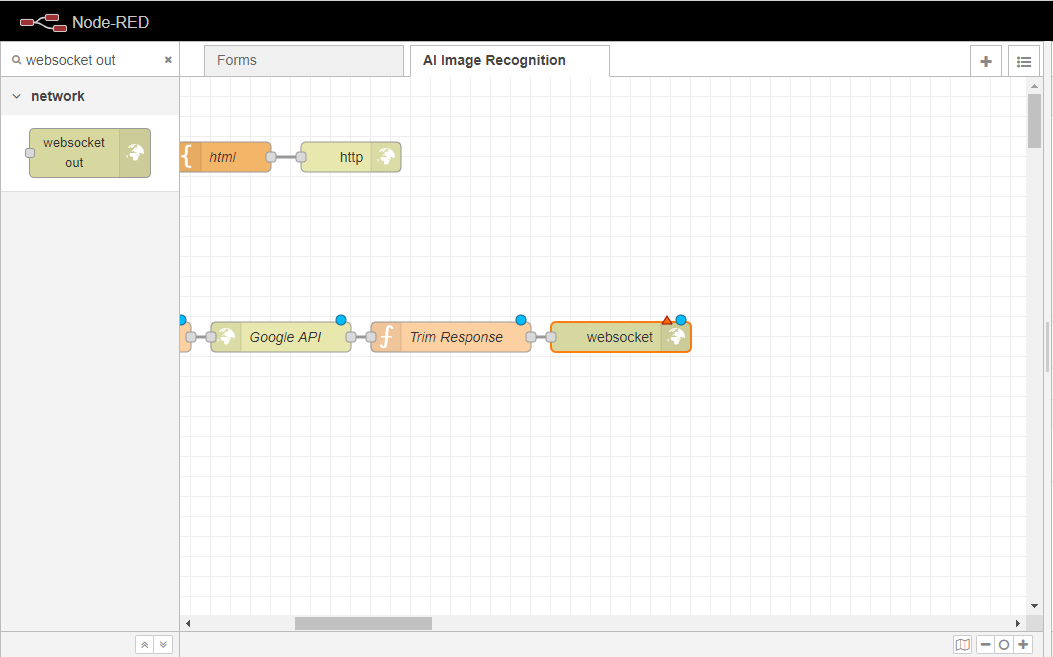
ウェブソケットアウトノードを2回クリックして、そのプロパティタブを開きます。
Add new websocket-listener…の右側にあるEditボタンをクリックします。
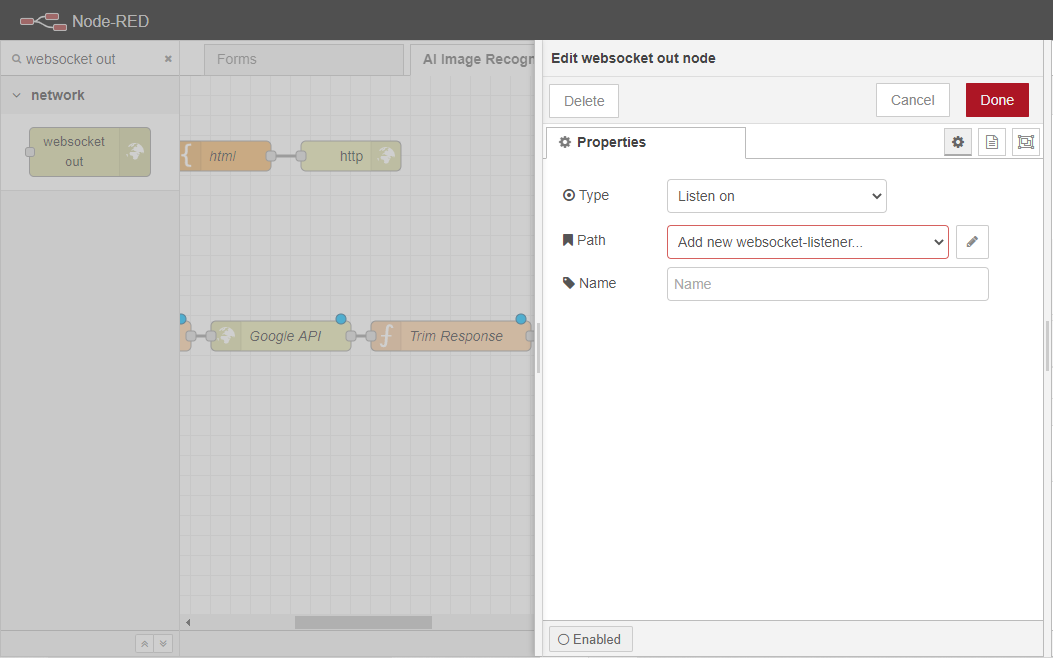
ウェブソケットのパスを/ws/google-vision-complex に設定します。
このウェブソケットを使用できるフローをAI 画像 認識フローのみに設定します。
Addボタンをクリックして、変更を保存します。その後、Doneボタンをクリックして、このノードの設定を終了します。
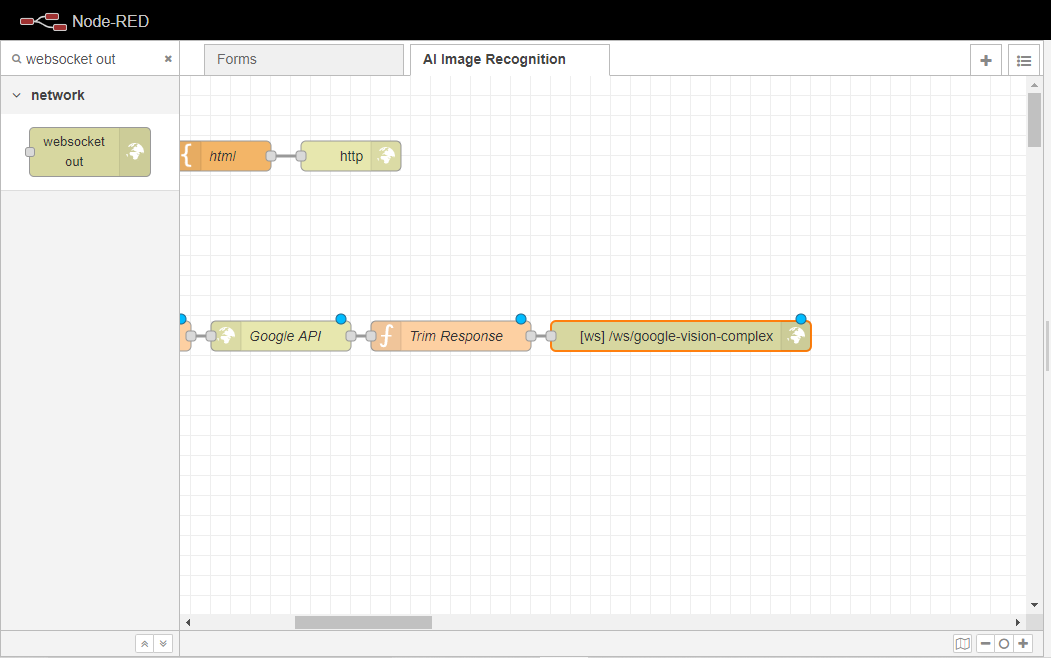
最後に、ワークスペースにデバッグノードを追加し、toBase64ノードに配線します。
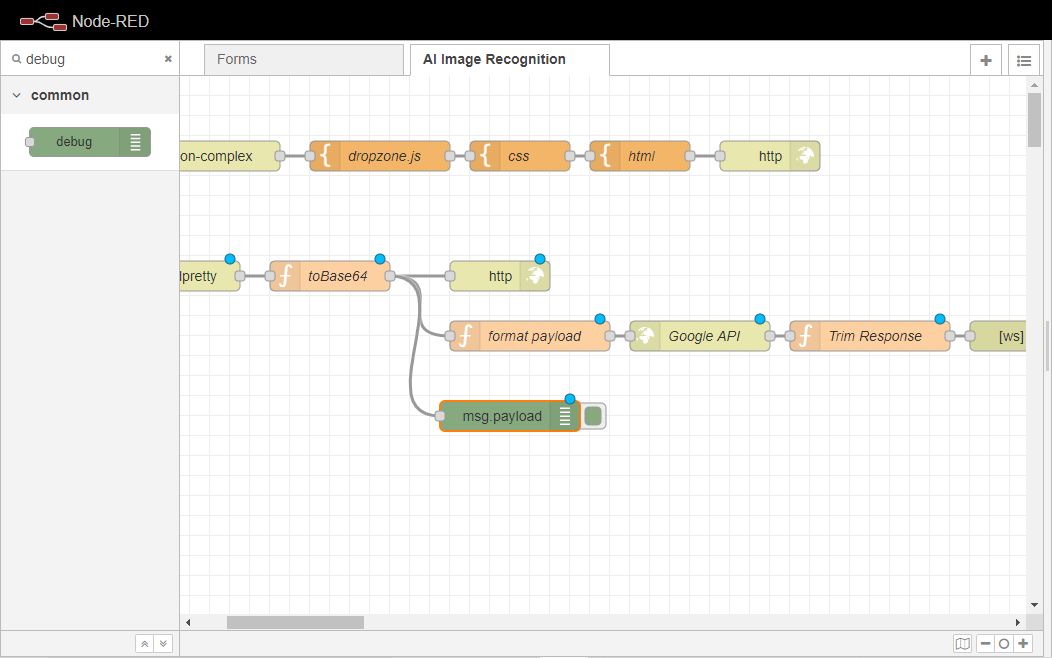
デバッグノードを2回クリックし、プロパティタブを開きます。
その出力を完全な msg オブジェクトとして設定します。
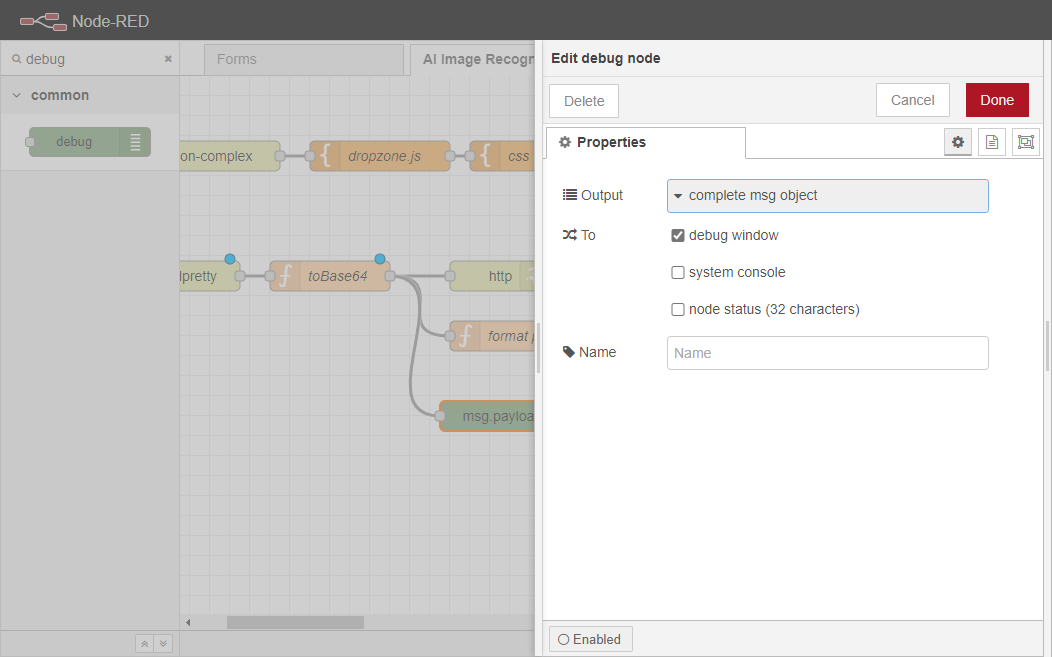
最後に、[Deploy]ボタンをクリックして変更をコミットします。ワークフローは以下の画像のようになるはずです。
以上です。これでこのフローの例は終わりです。これで、自分のNode-REDインスタンスに定義したサブロケーションに移動してテストすることができます。私の場合は、https://paulo.app.openiap.io/google-vision-complex。試してみてください。
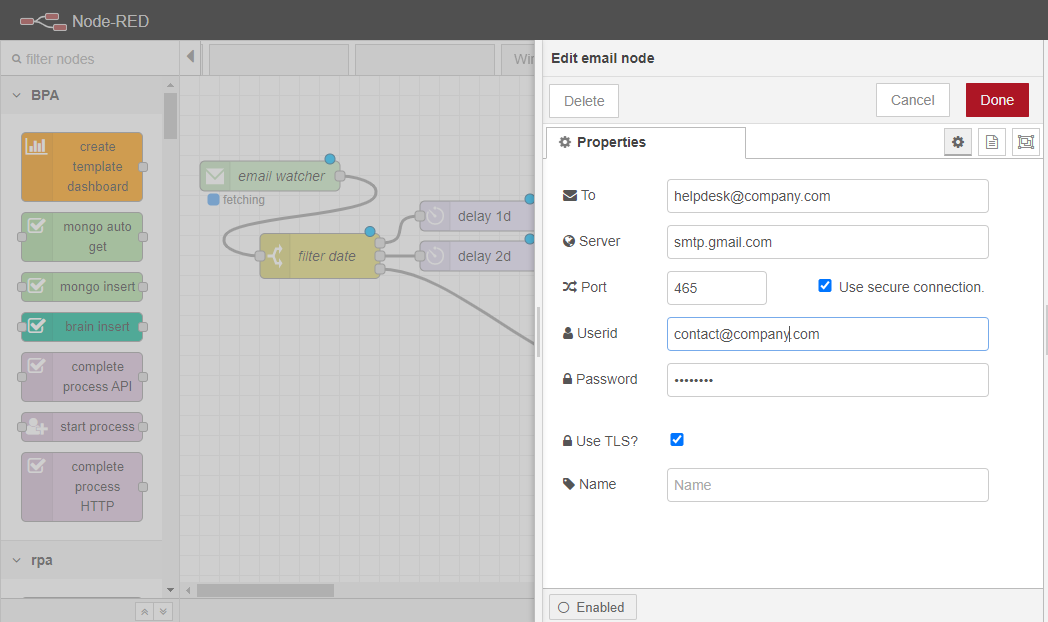
4.6.4.1. 電子メールを受信する
まず、「メールウォッチャー」、つまりIMAPサーバーから新しいメールを繰り返し検索し、メッセージとして転送するノードを設定します。このため、このノードには出力しかありません。このノードの設定は非常に直感的で自明ですが、いくつかの特徴を強調することが重要です。
ユーザーは、電子メールサービスにアクセスするために、電子メールIDとパスワードを提供する必要があります。また、「Disposition」パラメータを「None」に設定すると、ノードが未読の電子メールを検索するため、同じ電子メールに関するメッセージを常に送信するようになることに留意することが重要です。そのため、このパラメータは「既読マーク」に設定することをお勧めします。Port」パラメータは、推奨値(993)を使用することができます。
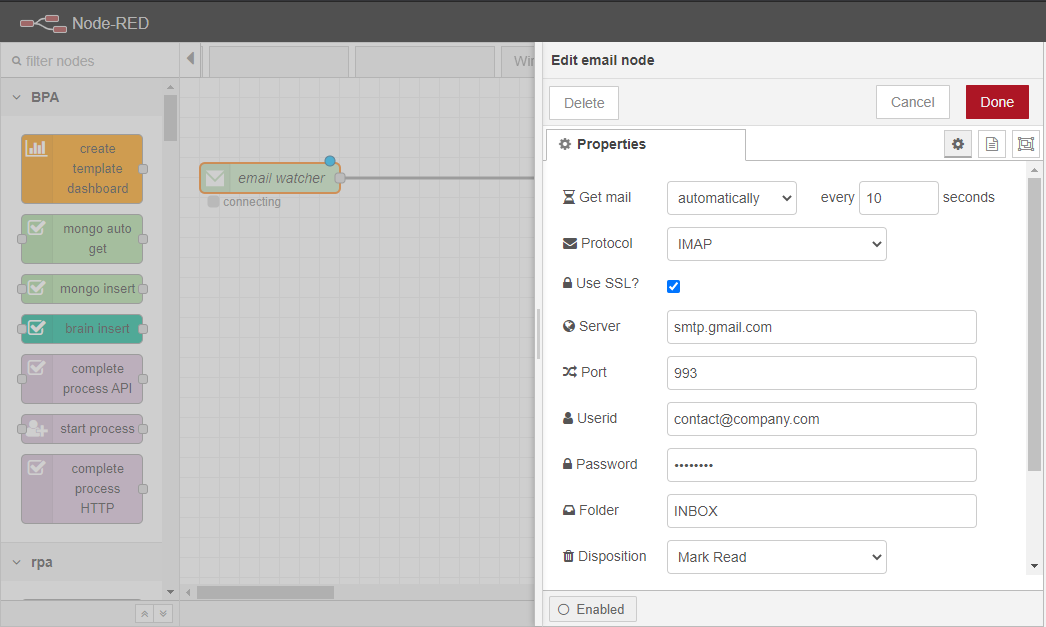
ただし、電子メールサービスによっては、この種のアプリケーションから電子メールアカウントにアクセスできない場合があります。そのため、より安全性の低いアプリケーションからのアクセスを可能にする必要があります。この例では、Gmailのアカウントを使用しました。Gmailで許可を与えるには、ユーザーは画面左上のアバターをクリックして、「Googleアカウントの管理」をクリックする必要があります。新しいタブが開き、ユーザーは「セキュリティ」をクリックします。オプションの1つは、「安全性の低いアプリを有効にする」です。このタイプのアプリを有効にすると、メールウォッチャーノードが選択した受信トレイにアクセスできるようになります。
4.6.4.2. 電子メールのリダイレクト
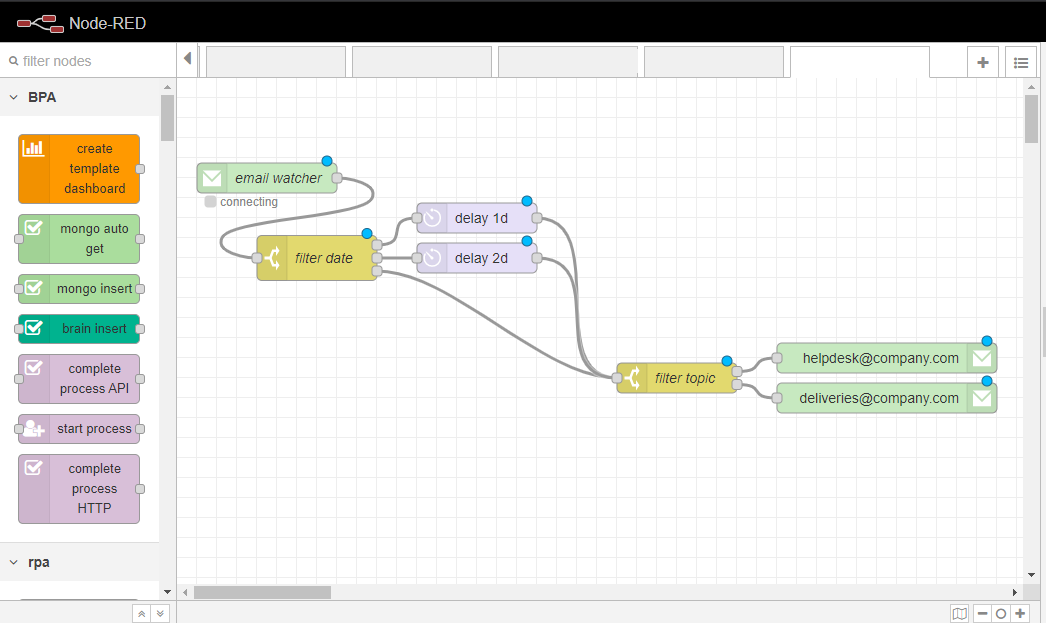
メッセージのフィルタリングには「switch」ノードが採用され、メッセージの複数のプロパティをフィルタリングのパラメータとして設定することができる。最も一般的なプロパティは、メールの本文に相当する「msg.payload」である。特定のキーワードが含まれているかどうかをチェックすることが可能になる。
msg.date(メールの送信日時を返す)、msg.from(送信者のメールアドレスを返す)など、他のプロパティを使用することも可能です。
この例では、msg.dateを使って、例えばDelayノードを使って週末に送信された電子メールのリダイレクトを次の月曜日に延期しています。使用されている「フィルター」は、実際にリダイレクトを実行するスイッチノードです。
4.6.4.3. 電子メールを送信する
電子メールを送信するには、ユーザーはもう1つのEmailノード(「電子メール送信者」)を採用することができます。これは入力を持つノードで、つまり、メッセージを受信し、選択されたアドレスに送信します。
また、送信者のメールアドレスとパスワードを入力し、選択したアカウントからメールを送信できるようにする必要があります。この例では、”e-mail watcher “としてアカウントを使用していますが、他のアカウントを使用することも可能です。つまり、新しい電子メールが見つかり、フロー内のメッセージとして送信されると、元のアカウントとの関連はなくなり、別のアカウントで送信される可能性があるということです。
4.6.5. HTTPエンドポイントの作成
-
APIの基本構造
-
データベースの作成と新規項目の追加
-
アイテム一覧を見る
4.6.5.1. APIの基本構造について
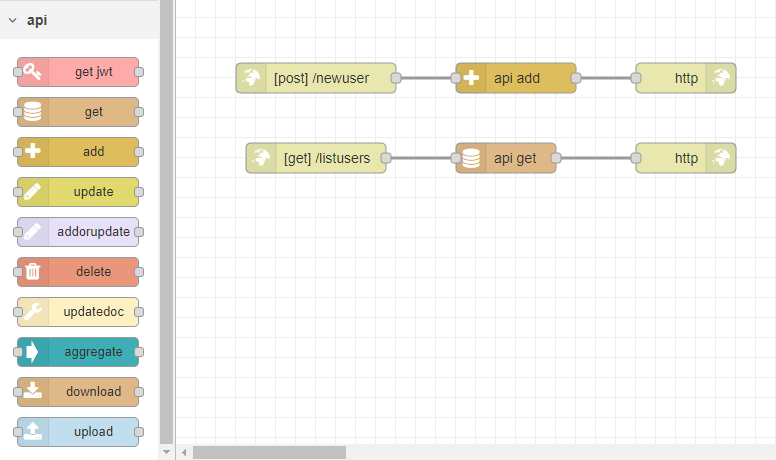
Node-RED で新しい HTTP エンドポイントを作成するには、2 つのノードだけが必要です。この2つのノードは必ず接続されなければならず、APIが適切にアクションを実行するために、他のノードがこの構造に追加されます。
ユーザーは、これら2つのノードをWorkspaceにドラッグして接続します。この2つのノードは、APIの各エンドポイントに必要です。 この最初のエンドポイントでは、ドメイン内で利用可能なすべてのエンドポイントを含むWebページを表示するとします。
HTMLページを追加するには、すでに作成されている2つのノードの間に新しいTemplateノードを追加します。このノードのプロパティで、「Syntax Highlight」フィールドをHTMLに変更する必要があります。その後、ユーザーはHTMLを使用してAPIのホームページを作成することができます。
最初のノード(HTTP In)は、フローをデプロイする前に設定する必要があります。その設定において、ユーザーは3つのフィールドを見つけることができます。メソッド、URL、名前です。このホームページでは、メソッドは「GET」、URLは「/homepage」が使用されます。
4.6.5.2. データベースを作成し、新しい項目を追加する
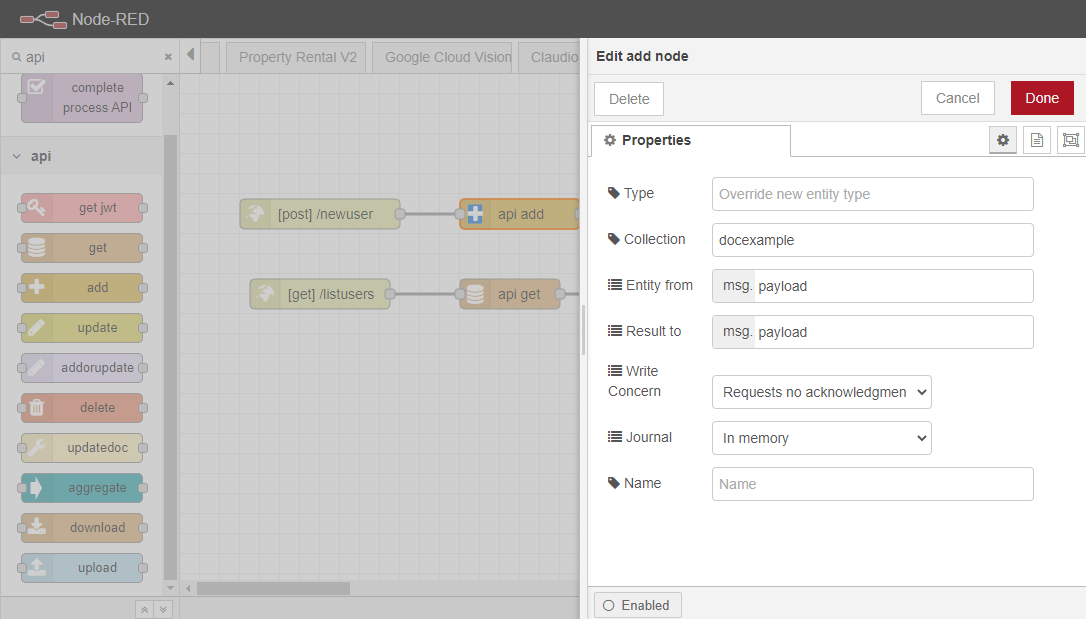
新しいデータベースは、ユーザーが新しいアイテムを追加した時点で作成されます。ユーザーは、情報を受け取って MongoDB のデータベースに追加することができる新しいエンドポイント (つまり、HTTP InとHTTP Responseノードが 1 つずつ接続されている) を作成することになります。この 2 つのノードのほかに、パレットのAPIカテゴリからAddノードを追加する必要があります。
その後、ユーザーはHTTP Inノードを設定する必要があります。ここで必要なアクションは、データベースに新しいアイテムを追加することなので、このエンドポイントのメソッドは「POST」になります。また、URLも設定する必要があります。この例では、”/newuser “です。
最後のステップは、addノードの設定です。 ユーザーは、ここに7つのフィールドを見つけることができます。Type,Collection,Entity from,Result to,Write Concern,Journal,Name です。このカテゴリのノードの完全な説明はMongoDB Entities にあります。この例では、コレクションの名前 (これもまだ存在しない場合は自動的に作成されます)、正しい入力 (「Entity from」)、出力 (「Result to」) を記入するだけです。
APIをテストするために、任意のAPIテスターを使用することが可能です。リクエストはノードの設定で指定したのと同じメソッド、つまり “POST “に従わなければなりません。リクエストのボディはMongoDBデータベースに追加されるため、JSON形式でなければなりません。レスポンスが “200” であった場合は、API が動作していることを意味します。
4.6.5.3. アイテムの全リストを取得する
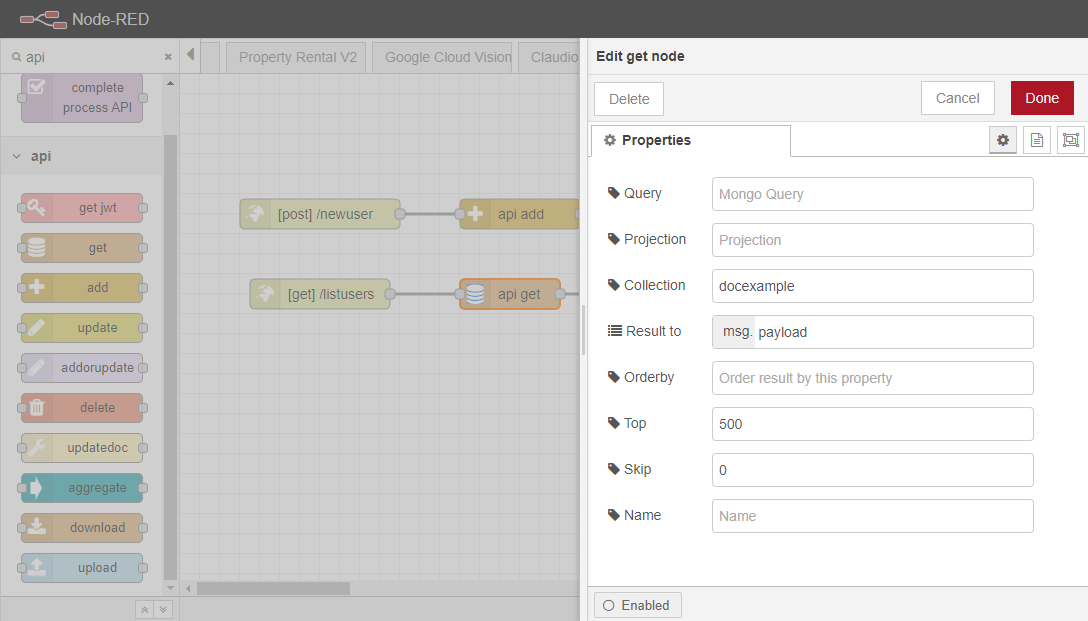
このAPIの最後のエンドポイントでは、すべてのアイテムのリストが取得される。フローの設計は同じで、HTTP Inノードが1つ、Get(Addの代わり)ノードが1つ、HTTP Responseノードが1つとなります。
この場合、HTTP Inノードのメソッドは “GET “に設定する必要があります。この例で使用されているURLは、”/listusers “です。
その後、ユーザーはgetノードを設定する必要があります。ユーザーの完全なリストを取得するには、「Query」フィールドを空白にする必要があります。必要であれば、「Query」フィールドを設定することで、このエンドポイントによって取得される情報を指定し、必要な情報を返すことができる。その後、ユーザーはコレクションの名前を入力する必要があります。
4.6.6. Excel検出器
この例では、Excel読み取りワークフローの例で作成したワークフローを自動的に実行する検出器を設定する方法について説明します。