
今回は紙の請求書をどのようにデジタル化・構造抽出するかについて確認していきたいと思います。
紙のデジタル化といえば、「OCR」ですので、今回はOCRと請求書について掘り下げていきます。
OCRとは
まずOCRとは何の略かというと
Optical Character Recognition(日本語では「光学文字認識」)
の略です。活字、手書きテキストの画像を文字コード(デジタルデータ)に変換するソフトウェアや技術を指します。
OCRの歴史は意外にも古く1920年代に研究・開発され、1929年にはアメリカで数字とアルファベットを読み取るOCRがそれぞれ開発され特許が出願されています。
日本においては1960年代に郵便物の仕分けのために大量の人員が動員されており、これを解決すべく郵便番号制度の検討とOCRの研究がスタートしました。日本では住所で使われる「漢字」の読み取りが難しいため、郵便番号制度とOCR機器の開発を同時に進める必要がありました。そして1968年7月に郵便番号制度が導入され、同月に東芝が国産OCRを初めて製品化し、本格的にOCRの利用が始まりました。

世界初の郵便物自動処理装置(TR-3/4)
https://toshiba-mirai-kagakukan.jp/learn/history/ichigoki/1967postmatter/index_j.htm
TR-3/4の基本仕様
- 赤枠内に記入された自由手書き数字を認識
- 読取可能桁数3桁
- 処理速度20,000通/時
自由手書きでは、使用する筆記用具、字の大きさと位置、線の太さと濃度など千差万別で、30万字にも及ぶサンプルを全国から集め、解析シミュレーションをもとに改良を重ね、実用機TR-3型とTR-4型を製造した。
これら日本のOCRの歴史は「OCR-コンピュータ博物館」でまとまっていますので、ご参照ください。
https://museum.ipsj.or.jp/computer/ocr/index.html
このように、OCRはビジネスの領域でも利用されるようになり、現在ではパソコンだけでなくスマートフォンアプリなどでも気軽に利用できるようになっています。
個人的におすすめなのは「Microsoft Lens」です。認識精度も高く、画像処理も優秀なので何かLensと連携するサービスを作れないか考えているところです。
OCRの基本的技術
ここでOCRの基本的技術を確認しておきたいと思います。
この後にAIの導入でこのあたりの基本的技術がどう進化していったかを理解していただくためにも、まずは基本を確認したいと思います。
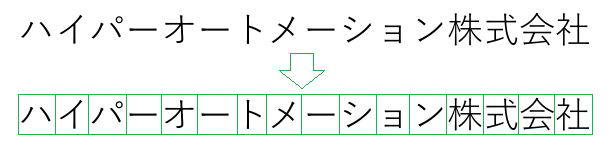
Step1.文字列領域切取(ユーザー指定)
まずはどこに文字列があるかユーザーが指定します。
サンプルでは(180,196)-(788,324)の座標に宛名が、(638,426)-(794,486)の座標に件名があると指定します。

実際には数字を指定する訳ではなく、OCRソフトの画面で指定しやすくなっています。また、この座標に正しく文字列が入っているように、画像の傾き補正などをする必要があります。
Step2.文字切取
文字列から文字を切り出します。
活字であれば文字と文字は重ならないので、長方形で切り出すことが可能です。
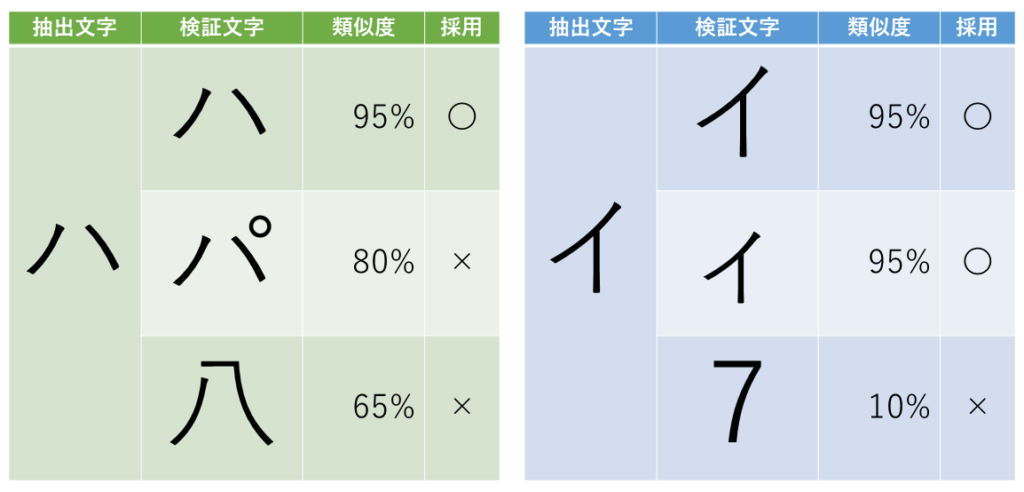
Step3.文字認識
文字がどの文字かOCRソフト内に持っている文字データベースと付け合わせして、一番類似度が高いものを選択します。
英数字だけであれば大文字小文字区別した場合でも62文字で文字数が少ないので比較しやすいです。
日本語はひらがな・カタカナだけでなく漢字も含まれ、たとえばカタカナは同じ形でも大文字小文字・全角半角があるので間違って認識してしまうパターンが多いですし、漢字はさらに常用漢字と人名用漢字の合わせて約3,000字程度あるので、どの文字が正確に判断するのかは非常に難しいです。
さらに、書体(フォント)でも文字の形が違うので、多くの書体で多くの文字をOCRソフト内に文字データベースとして持つ必要があります。
Step4.辞書マッチング
文字認識の段階で複数のパターンが考えられる場合は、OCRソフト内の辞書とマッチングさせます。
「ハイパー」(イが大文字)⇒辞書にあるので正しそう
「ハィパー」(イが小文字)⇒辞書にないので間違っていそう
これらを見ると、OCRの文字認識に何が大切か分かります。
- 傾き補正など適切な前処理(画像処理)ができること
- 多くのフォント・文字の文字データベースを持っていること
- 多くの辞書を持っていること
例えば、PanasonicのAI-OCR対応ソフト「AI帳票OCR Ver.9(WisOCR)」の仕様を見てみると、対応している文字数などが分かります。
https://www.panasonic.com/jp/business/its/ocr_form/spec_1.html
AI-OCRとは
一般にAI-OCRと言われますが、技術的には3つの体系があります
Text Recognition AI(文字認識)
AI-OCRでよく言われる「手書き」文字に対応したものとなります。
手書き文字はOCRソフト内に持っている文字データベースではヒットしないため、文字判定が非常に難しいです。
綺麗な手書き文字であれば良いのですが、崩れていたり・傾いていたりなど人間であっても読みにくい文字もあります。
さらに、文字と文字が重なることがあり、きれいに文字単位で長方形で切れない場合もあります。
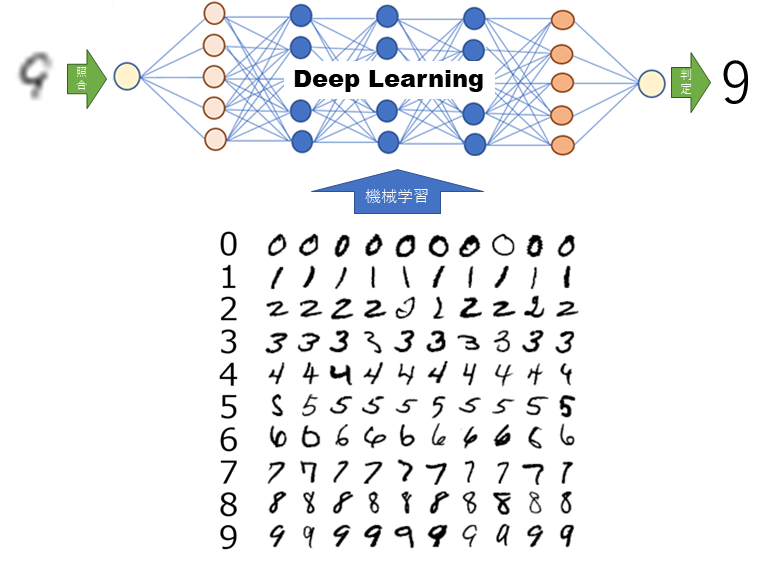
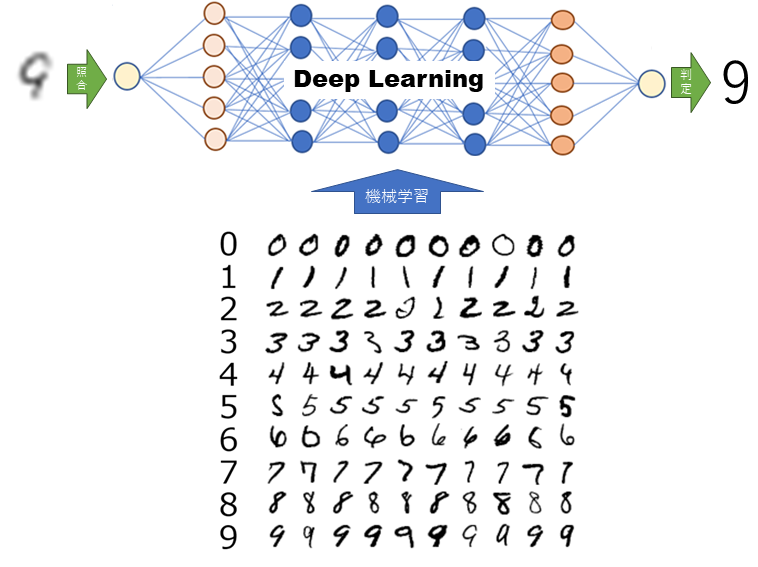
これらをAIの深層学習(ディープラーニング)を用いた画像認識システムにより文字データベースに無い文字でも文字認識することが可能となりました。
Context Recognition AI(文脈認識)
文章の意味が正しくなるように、AIが自動的に補正する技術です。
特に、「間違えやすいもの」を文脈から自動修復するところで機能します。

機能的には辞書マッチングで補正できる部分もありますが、それをもっと文脈を意識して修正してくれます。
Text Detection AI(文字領域検出)
基本技術「文字列領域切取」では画像内の座標を指定しなければいけないという話をしました。
しかしText Detection AIでは画像内の文字列と文字列の関係性から、取得したい文字列を取得することが可能です。
たとえば「請求日」を画像内から取得したい場合は、「請求日」という文字列のある右側の文字列を取得します。一般的に項目名の右側に値があるので、このルールで取得できます。
また、宛名は「御中」や「様」という左側(前側)にあるので、左側にある文字列を取得します。
さらに、その左側にある文字列に「株式会社」や「有限会社」という文字が含まれている場合は宛名の可能性がさらに高いです。

このようにすることで、座標を指定しなくても、取得したい項目名を指定すれば必要な文字列(値)を取得できるようになります。特に請求書であれば読み取りたい項目は限られているので、このルールを細かく設定すれば、請求書から取得したい内容は取得できます。
※実際に別途紹介するABBYY FlexiCaptureという製品では、このルールを非常に細かく設定できます。
ただ、ここまでの話でしたらAIでなくても実現できます。
世の中にはルールで表現できないパターンの請求書も多くあるため、各OCRサービスベンダーはAIによる機械学習にてこの認識精度を高めています。実は結構、枚数の多い公共系(電気・水道・ガス)の請求書がルール定義では難しいため(余計な文字が多すぎる!!)、AIが活躍しているところです。
例)NTT東日本
https://web116.jp/ryoukin/payment/form01.html
日々進化するOCR
AI-OCRは日々進化しており、たとえば最近のニュースでは凸版印刷が古文書などで利用されている「くずし文字」のOCRをサービス化しました。
「AI OCR」でくずし字を解読、開発に6年を費やした凸版印刷の狙い
https://xtech.nikkei.com/atcl/nxt/column/18/00001/05251/
特開2021-149737 くずし字認識システム、くずし字認識方法、データセットの作成方法、及びプログラム
https://www.j-platpat.inpit.go.jp/c1800/PU/JP-2021-149737/939D2F21E59AF35D4ADCECBEE290962909349DCD5E48156C842312E0ED50FA01/11/ja
前回のコラムでもふれたように「年間5,500億を超える請求書を交換しており、その数は2035年までに4倍になると予測されている」ので、当面まだ私たちは紙請求書と付き合う必要があります。
そのデジタル化のためにも、AI-OCRの進化にはこれからも期待したいと思います。
次回は、実際どのようなAI-OCRサービスがあって、各社のメリットや、そもそもハイパーオートメーションの観点からどのようにしていくべきか述べていきたいと思います。